在这篇文章里我们将会解释在 Post not found: introduction-virtio-networking-and-vhost-net [introduction] 里描述的vhost-net架构,并通过技术视角来弄清楚所有东西是怎么协同工作的。这系列博客里的这部分内容是为了让你们更好的理解virtio-networking领域是如何将虚拟化和网络连接在一起的
本文主要主要是面向对有兴趣理解上一篇blog提到的vhost-net/virtio-net底层原理的架构师和研发人员
我们将从描述不同的virtio规范的标准组件和共享内存在hypervisor里如何组织的,QEMU如何模拟一个virtio网络设备以及一个guest使用根据virtio规范来实现一个虚拟化驱动来管理并和设备通讯的
在展示过QEMU virtio架构,我们将会分析I/O瓶颈和限制,同时我们将会用host的kernel来解决这个问题,同时最后给出一个宏观的vhost-net的架构
最后,我们将会展示如何通过在它所运行的host上使用OVS(一个开源的虚拟化,SDN,分布式交换机)连接虚拟机到外部网络
希望在读完这篇文章后,你能够理解vhost-net/virtio-net架构是如何工作的,同时能够理解这架构中每一个组件的目标和作用以及数据包是如何被发送和接收的
Previous Concepts
在这个部分我们将会简短的介绍一些帮助你完全理解这篇文章需要知道的概念。对于精通这个问题的人是比较基础的内容,但主要是为了提供一个共同的基础
Networking
让我们从最基础的开始。一个物理网卡(Nic,Network Interface Card)是一个真实的硬件组件,允许物理机连接到外部网络。网卡可以承担一些offload,比如代替CPU执行checksum计算,Segmentation Offload(把一个很大片的数据转换成很多切片,切片大小就是以太网MTU的大小)或者是Large Receive Offload(从CPU角度看,就是把很多数据包合成一个数据包)
另外我们还有tun/tap设备,虚拟化的用户态用来交换数据包的点对点网络设备。交换二层(ethernet frames)数据的叫做tap设备,如果交换 (IP packets)三层数据的就是tun设备。
当tun的kernel模块被加载之后会创建一个特殊的/dev/net/tun设备。进程可以创建tap设备,并发打开这个设备发送一些特殊的ioctl命令给这个设备。新创建的tap设备在。dev文件系统里存在一个名字,并且其他的进程可以打开,并发送接收Ethernet frames
IPC,System programming
Unix sockets是一个在同一台物理机器上做进程间通信的有效方法。在这篇文章涉及的范围内,通讯的服务端监听了文件系统上一个路径下的Unix socket,因此一个客户端(client)可以连接到这个路径使用它。这样,进程间就可以交换消息了。注意,unix sockets也可以用来在进程间交换文件描述符。
eventfd是一个轻量级IPC的实现。虽然Unix sockets允许发送和接收各种消息,eventfd只是一个生产者可以修改,消费者可以读取的整型值。这个使得eventfd更适合用于等待通知机制,而不是传输信息的场景。
这两个IPC系统都为通信中的每个进程公开一个文件描述符。 fcntl调用对该文件描述符执行不同的操作,使它们成为非阻塞的(因此,如果没有可读取的内容,则读取操作会立即返回)。 ioctl调用遵循相同的模式,但实现特定于设备的操作,例如发送命令。
共享内存是我们要介绍的最后一个IPC方法。不同于提供一个进程间通讯的channel,共享内存使用进程的内存区域指向相同的内存页面,因此一个进程覆盖了这部分内存的修改也会影响其他进程之后的读操作。
QEMU and device emulation
QEMU是一个host层的虚拟机模拟器,给guest提供了一系列不同的硬件和设备模型。对host来说,qemu是一个标准Linux可调度的标准进程,有自己的进程内存。在进程里QEMU分配了内存区域来给guest当作物理内存么,同时QEMU还要执行虚拟机的CPU指令
为了在裸机设备上执行I/O操作么,比如存储和网络,CPU必须给物理设备下发特殊的指令并访问特殊的内存区域,比如这个设备被映射到的内存区域
当guest访问这些内存区域的时候,控制面就返回到了执行设备透明模拟的guest的QEMU里
KVM
Kernel-based Virtual Machine(KVM)是一个Linux内置的开源虚拟化技术。它为虚拟化软件提供硬件辅助,利用内置CPU虚拟化技术减少虚拟化开销(缓存、I/O、内存),提高安全性。
使用KVM,QEMU可以创建一个虚拟机,该虚拟机具有处理器识别的虚拟 CPU (vCPU),运行native-speed指令。当特殊的比如需要和设备或者特殊内存交互的命令到达KVM的时候,vCPU会停下来,然后通知QEMU暂停的原因,然后hypervisor就会对这个事件作出反应了。
在常规的KVM操作里,hyervisor会打开/dev/kvm这个设备,然后通过ioctl和他通讯调用它创建虚拟机,增加CPU,增加内存(qemu分配,但是虚拟机看来是物理内存),发送CPU中断(外部设备引发的),等等。举个例子,某一个ioctl的命令运行了KVM vCPU,阻塞了QEMU而且vCPU需要等到它找到了需要硬件辅助的命令。那时ioctl就会返回(这个叫做vmexit)同时QEMU也能知道这个exit的原因(比如offending instruction)。
对一些特别的内存区域,KVM有类似的访问方式,把内存区域标记为只读或者完全不映射,通过KVM_EXIT_MMIO造成一个vmexit。
The virtio specification
Virtio specification: devices and drivers
Virtio是一个虚拟机数据I/O的一个开放规范,提供了简单、有效、标准并且可拓展的虚拟设备机制,而不是固定在在每个环境或每个操作系统的机制。它主要基于guest可以和host共享内存以进行I/O来实现。
virtio规范基于两个元素:设备和驱动。在最经典的实现里,hypervisor通过一系列传输方法试将virtio设备暴露给guest。设计上他们在虚拟机内看起来是物理设备。
嘴常见的传输方法就是PCI或者PCIe总线。然而,这些设备在一些预定义好的guest内存地址是可用的(MMIO transport)。这些设备可以完全在没有物理设备或者是物理的兼容性接口的情况下被虚拟出来。
最典型最简单的暴露virtio设备的方法是通过PCI端口因为我们可以借用PCI已经是一个成熟并且在QEMU和Linux驱动自持的很好的协议。实际的PCI硬件通过特殊的物理内存地址范围和/或特殊的处理器指令暴露配置空间(比如,驱动可以通过这些内存范围读或者写设备的寄存器)。在虚拟机世界里,hypervisor能捕获访问这些内存范围并且执行设备模拟,暴露和真实设备相同的内存布局,并提供相同的返回。virtio标准也定义了PCI配置空间的布局,因此实现它是很简单的。
当guest驱动并使用PCI/PCI自动发现机制的时候,virtio设备通过PCI vendor ID和他们的PCI device ID标识自己。guest kernel通过使用这些标记来知道使用哪些驱动来处理这些设备。特别是,linux内核已经包含了virtio驱动程序。
virtio驱动必须能够分配给hypervisor和设备都能读写的内存区域,比如通过共享内存。我们把数据平面作为使用内存区域进行数据通讯的一个部分,同时控制平面主要是来配置他们。我们会在后续的文章里提供一个更深层次的virtio协议的实现细节以及内存布局。
virtio内核驱动共享了一个通用的传输专用接口(virtio-pci),并被用于实际的传输以及设备实现(比如virtio-net,virtio-scsi)
Virtio specification: virtqueues
Virtqueues是virtio设备的批量数据传输机制。每个设备可以有0个或者多个virtqueue link。它由guest分配的host可以访问并且可以读或者写的缓存队列组成。补充一下,virtio标准也定义了双向的通知:
- Available Buffer Notification:使用驱动来通知buffer就绪并可以被设备处理
- Used Buffer Notification:被设备使用来通知已经处理完了一些buffers
在PCI的场景,guest通过写一个特殊的内存地址发送available buffer notification,然后设备(这个场景里是QEMU)使用vCPU中断来发送used buffer notification。
virtio规范也允许notifications动态的启用或者停用。这种情况下设备和驱动可以批量的缓存通知或者主动的向virtqueues请求新的缓存。这个方法更适合高流量的场景。
总结一下,virtio驱动接口暴露了一下内容:
- Device’s feature bits(设备和guest需要协商的部分)
- Status bits(状态位)
- Configuration space(包含设备特殊信息,比如MAC地址)
- Notification system(配置变更,缓存可用,缓存使用)
- Zero or more virtqueues
- Transport specific interface to the device
Networking with virtio: qemu implementation
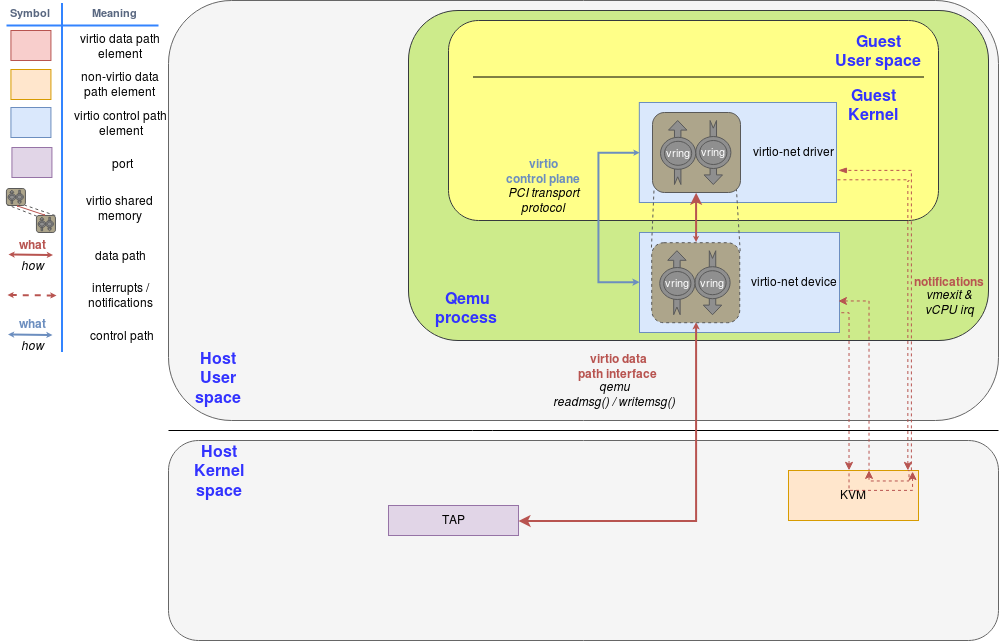
Figure 1: virtio-net on qemu
virtio网络设备是一个虚拟以太网卡,支持TX/RX(发送,接收)多队列。空的缓存被放在N virtqueues里用来接收数据包,往外送的数据包责备放到另外一个N virtqueues里面等待发送。另一个virtqueue被用于数据面之外的驱动和设备的通讯,比如控制高级过滤特性,设置mac地址,或者是一堆活跃的队列。像物理网卡一样,virtio设备支持很多特性比如offloading,能够让真实的host设备来处理。
为了发送数据包,驱动会发送给设备一个缓存包括metadata信息比如在要发送的packet frame上带有的数据包期望的offloading。驱动能够将这个缓存拆分成不同的条目,比如可以把这个metadata的header从packet frame上分离出来。
这些缓存被驱动管理,被映射给设备。因此这个情况下我们可以说这个设备实际上在hypervisor里(结合前面提到hypervisor)因为qemu能够访问所有的guest内存,所以有能力知道缓存的位置并能够对他们进行读写。
下面的流程图表示了virtio-net设备配置和使用virtio-net驱动发送数据包通过PCI和virtio-net设备通讯。在组装好要发送的数据包之后,出发了一个available buffer notification,把控制返回给QEMU然后它就能够把包通过TAP设备送出去
QEMU然后通知guest这些缓存操作执行完成了(读或者写)并且它通过把这些数据放到virtqueue然后发送一个used notification event来触发guest的vCPU中断。
接收数据包的过程和发送类似。唯一不同的是在接收数据包的场合,空缓存会提前被guest分配出来然后提供给设备一个可用缓存保证它能够把即将收到的数据写进去。
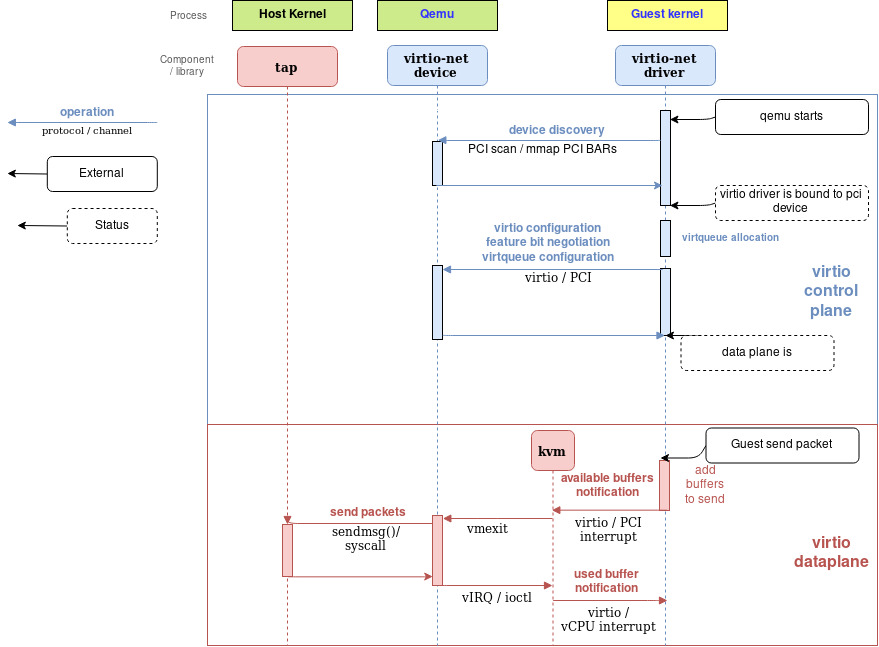
Figure 2: Qemu virtio sending buffer flow diagram
Vhost-net
vhost-net是一个内核驱动,实现了vhost协议的处理侧,用来实现一个高效的数据面。比如数据包转发,在这个实现里,qemu和vhost-net内核驱动(handler)使用ioctls来交换vhost消息和一大批叫做irqfd的类似eventfd的文件描述符然后ioeventfs被用来和guest交换通知
当vhost-net驱动被加载的时候,它会在/dev/vhost-net暴露一个字符设备。当qemu启用了vhost-net并启动后,它会打开这个设备并且一些ioctl调用初始化vhost-net实例。这是把vhost-net和hypervisor联系起来必不可少的步骤,准备virtio特性检查,然后给guest提供映射到vhost-net驱动的内存。
在初始化的过程里vhost-net驱动创建了一个内核线程叫做vhost-$pid这个$pid就是hypervisor(也就是qemu进程)的pid。这个线程也被叫做“vhost worker thread”
tag设备仍然被用于VM和host的通讯但是现在这个worker thread处理了这些I/O事件,比如它会不断poll驱动的通知或者是tap的事件并且做数据的转发。
Qemu分配了一个eventfd然后注册了到了vhost和KVM来实现通知的传递。vhost-pid内核线程poll这个eventfd,当guest写某一个特殊地址的时候KVM则会写这个eventfd。这个机制被叫做ioeventfd。用这个方法,对一个特别的guest内存地址简单的读写操作不需要再穿过钢轨的QEMU进程唤醒同时能够被直接路由到vhost worker thread。这也提供了异步的优势,也不再需要vCPU停下来(因此没必要立刻做上下文切换)
另一方面,qemu分配了另外的eventfd并再次注册他们到KVM和vhost来处理vCPU的直接中断注入。这个机制又叫irqfd,他们允许host通过写irqfd来注入vCPU中断到guest。同时也具有异步特性,不需要立刻做上下文切换
注意这些改动对virtio包处理后端对guest来说是完全透明的,guest仍然使用的是标准的virtio接口
下面的图展示了qemu数据路径的offloading到vhost-net内核驱动:
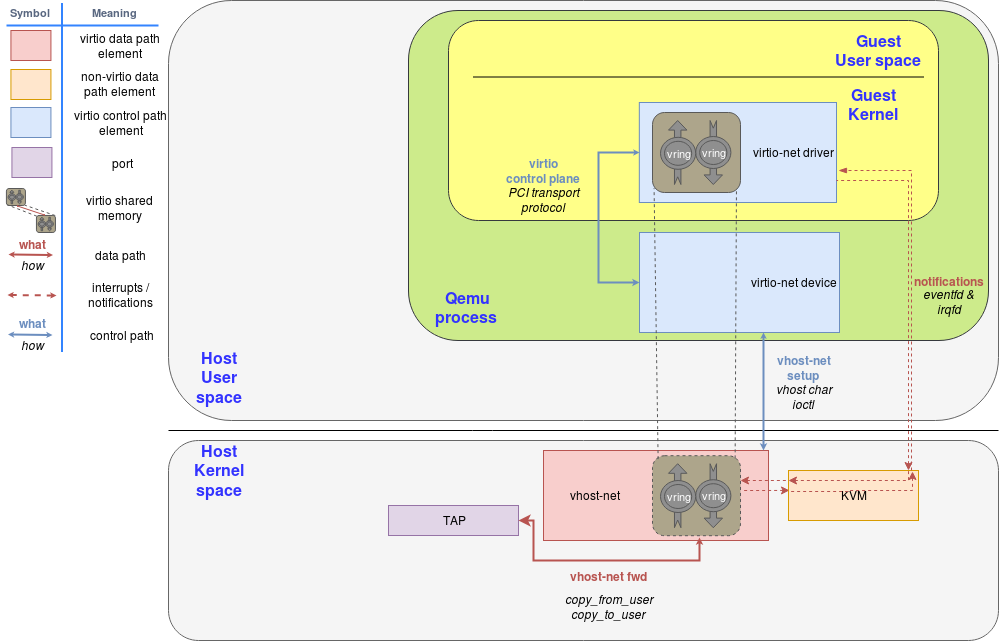
Figure 3: vhost-net block diagram
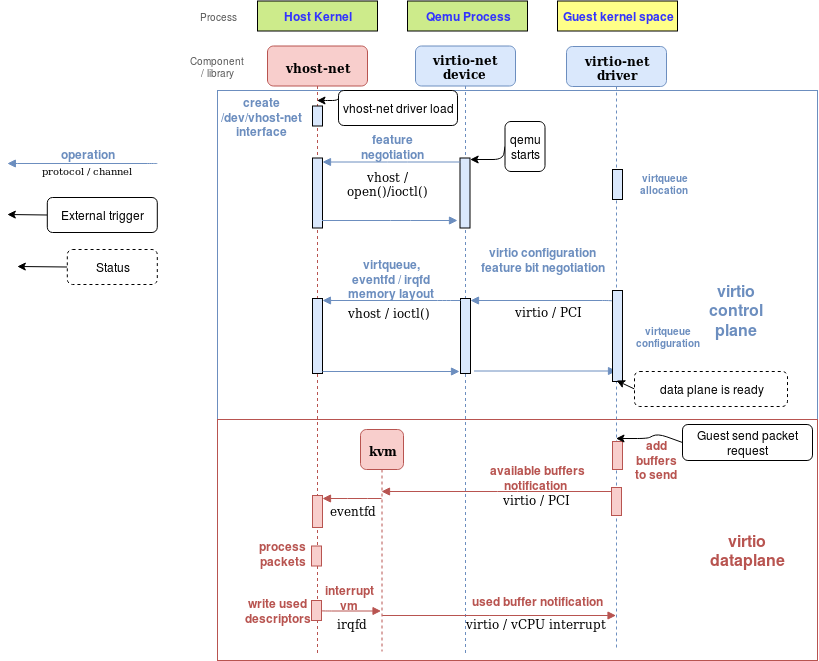
Figure 4: vhost-net sending buffer diagram flow
Communication with the outside world
guest能够和host通过tap设备通讯,然而还有一个遗留的问题就是guest如何和同一个host伤的其他vm或者是其他host上的vm通讯(使用internet通讯)
我们可以内核网络协议栈提供的转发和路由的机制,比如标准的Linux bridges。然而一个更加高级的解决方式就是一个全虚拟化的分发,管理交换机比如Open Virtual Switch
就像在总览篇说的一样,OVS的数据路径在这个场景里是作为内核模块运行的,ovs-switchd是一个用户态的控制管理守护进程然后ovsdb-server是一个转发数据库。
就像图上画的一样,OVS的数据路径在kernel运行然后在物理网卡和虚拟TAP设备间做包的forward:
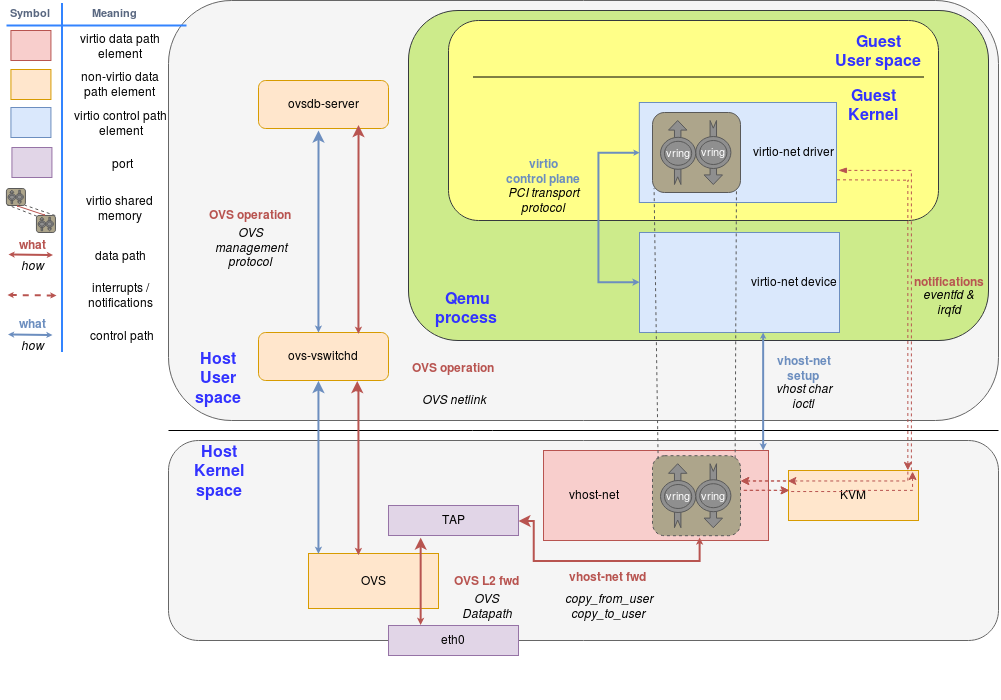
Figure 5: Introduce OVS
总结
在这篇文章里,我们展示了virtio-net的架构是如何工作的,我们对每一个步骤做了详细的解剖并解释了每个组件的功能。
我们开始解释了默认的qemu IO设备如何通过提供给guest一个开放virtio标准的实现来运作的。我们接下来分析了guest如何和这些设备通过virtio驱动能够发送和接收数据包,发送和接收通知的
然后我们评价了在数据路径中有qemu的情况下需要切换上下文,然后展示了如何在host上使用vhost协议通过vhost-net内核驱动offload这些任务。我们也能够覆盖virtio通知在这个新设计下是如何工作的
最后我们展示了如何将VM连接到外部的非自己所在的host的世界。
在接下来的文章里我们将会提供一个使用之前学习到的解决方案里的不同组件完成关于vhost-net/virtio-net的架构实现。
如果你因为什么原因跳过了那篇文章,我们将在下一篇文章介绍一个新的用户态的使用DPDK的vhost处理协议。我们会列举他的优点,使用DPDK和用户态的观点,我们将建立第二个符合这些概念的架构。