git clone https://github.com/tianocore/edk2.git cd edk2 git submodule update --init
than setup environment variables:
1
source edksetup.sh
build base tools at first:
1
make -C BaseTools
note: only need once
Build firmware
Then build firmware for x64 qemu:
1
build -t GCC5 -a X64 -p OvmfPkg/OvmfPkgX64.dsc
The firmware volumes built can be found in Build/OvmfX64/DEBUG_GCC5/FV.
Building the aarch64 firmware instead:
1
build -t GCC5 -a AARCH64 -p ArmVirtPkg/ArmVirtQemu.dsc
The build results land in Build/ArmVirtQemu-AARCH64/DEBUG_GCC5/FV.
Qemu expects the aarch64 firmware images being 64M im size. The firmware images can’t be used as-is because of that, some padding is needed to create an image which can be used for pflash:
There are a bunch of compile time options, typically enabled using -D NAME or -D NAME=TRUE. Options which are enabled by default can be turned off using -D NAME=FALSE. Available options are defined in the *.dsc files referenced by the build command. So a feature-complete build looks more like this:
# # Flash size selection. Setting FD_SIZE_IN_KB on the command line directly to # one of the supported values, in place of any of the convenience macros, is # permitted. # !ifdef $(FD_SIZE_1MB) DEFINE FD_SIZE_IN_KB = 1024 !else !ifdef $(FD_SIZE_2MB) DEFINE FD_SIZE_IN_KB = 2048 !else !ifdef $(FD_SIZE_4MB) DEFINE FD_SIZE_IN_KB = 4096 !else DEFINE FD_SIZE_IN_KB = 4096
Secure boot support (on x64) requires SMM mode. Well, it builds and works without SMM, but it’s not secure then. Without SMM nothing prevents the guest OS writing directly to flash, bypassing the firmware, so protected UEFI variables are not actually protected.
Also suspend (S3) support works with enabled SMM only in case parts of the firmware (PEI specifically, see below for details) run in 32bit mode. So the secure boot variant must be compiled this way:
1 2 3 4 5
build -t GCC5 -a IA32 -a X64 -p OvmfPkg/OvmfPkgIa32X64.dsc \ -D FD_SIZE_4MB \ -D SECURE_BOOT_ENABLE \ -D SMM_REQUIRE \ [ ... add network + tpm + other options as needed ... ]
The FD_SIZE_4MB option creates a larger firmware image, being 4MB instead of 2MB (default) in size, offering more space for both code and vars. The RHEL/CentOS builds use that. The Fedora builds are 2MB in size, for historical reasons.
If you need 32-bit firmware builds for some reason, here is how to do it:
1 2
build -t GCC5 -a ARM -p ArmVirtPkg/ArmVirtQemu.dsc build -t GCC5 -a IA32 -p OvmfPkg/OvmfPkgIa32.dsc
The build results will be in in Build/ArmVirtQemu-ARM/DEBUG_GCC5/FV and Build/OvmfIa32/DEBUG_GCC5/FV
Booting fresh firmware builds
The x86 firmware builds create three different images:
OVMF_VARS.fd
This is the firmware volume for persistent UEFI variables, i.e. where the firmware stores all configuration (boot entries and boot order, secure boot keys, …). Typically this is used as template for an empty variable store and each VM gets its own private copy, libvirt for example stores them in /var/lib/libvirt/qemu/nvram.
OVMF_CODE.fd
This is the firmware volume with the code. Separating this from VARS does (a) allow for easy firmware updates, and (b) allows to map the code read-only into the guest.
OVMF.fd
The all-in-one image with both CODE and VARS. This can be loaded as ROM using -bios, with two drawbacks: (a) UEFI variables are not persistent, and (b) it does not work for SMM_REQUIRE=TRUE builds.
qemu handles pflash storage as block devices, so we have to create block devices for the firmware images:
The core edk2 repo holds a number of packages, each package has its own toplevel directory. Here are the most interesting ones:
OvmfPkg
This holds both the x64-specific code (i.e. OVMF itself) and virtualization-specific code shared by all architectures (virtio drivers).
ArmVirtPkg
Arm specific virtual machine support code.
MdePkg, MdeModulePkg
Most core code is here (PCI support, USB support, generic services and drivers, …).
PcAtChipsetPkg
Some Intel architecture drivers and libs.
ArmPkg, ArmPlatformPkg
Common Arm architecture support code.
CryptoPkg, NetworkPkg, FatPkg, CpuPkg, …
As the names of the packages already suggest: Crypto support (using openssl), Network support (including network boot), FAT Filesystem driver, …
Firmware boot phases
The firmware modules in the edk2 repo often named after the boot phase they are running in. Most drivers are named SomeThing**Dxe** for example.
ResetVector
This is where code execution starts after a machine reset. The code will do the bare minimum needed to enter SEC. On x64 the most important step is the transition from 16-bit real mode to 32-bit mode or 64bit long mode.
SEC (Security)
This code typically loads and uncompresses the code for PEI and SEC. On physical hardware SEC often lives in ROM memory and can not be updated. The PEI and DXE firmware volumes are loaded from (updateable) flash.
With OVMF both SEC firmware volume and the compressed volume holding PXE and DXE code are part of the OVMF_CODE image and will simply be mapped into guest memory.
PEI (Pre-EFI Initialization)
Platform Initialization is done here. Initialize the chipset. Not much to do here in virtual machines, other than loading the x64 e820 memory map (via fw_cfg) from qemu, or get the memory map from the device tree (on aarch64). The virtual hardware is ready-to-go without much extra preaparation.
PEIMs (PEI Modules) can implement functionality which must be executed before entering the DXE phase. This includes security-sensitive things like initializing SMM mode and locking down flash memory.
DXE (Driver Execution Environment)
When PEI is done it hands over control to the full EFI environment contained in the DXE firmware volume. Most code is here. All kinds of drivers. the firmware setup efi app, …
Strictly speaking this isn’t only one phase. The code for all phases after PEI is part of the DXE firmware volume though.
Add debug to EDK2
The default OVMF build writes debug messages to IO port 0x402. The following qemu command line options save them in the file called debug.log:
The RELEASE build target (‘-b RELEASE’ build option, see below) disables all debug messages. The default build target is DEBUG.
more build scripts:
On systems with the bash shell you can use OvmfPkg/build.sh to simplify building and running OVMF.
So, for example, to build + run OVMF X64:
1 2
$ OvmfPkg/build.sh -a X64 $ OvmfPkg/build.sh -a X64 qemu
And to run a 64-bit UEFI bootable ISO image:
1
$ OvmfPkg/build.sh -a X64 qemu -cdrom /path/to/disk-image.iso
To build a 32-bit OVMF without debug messages using GCC 4.8:
1
$ OvmfPkg/build.sh -a IA32 -b RELEASE -t GCC48
UEFI Windows 7 & Windows 2008 Server
One of the ‘-vga std’ and ‘-vga qxl’ QEMU options should be used.
Only one video mode, 1024x768x32, is supported at OS runtime.
The ‘-vga qxl’ QEMU option is recommended. After booting the installed guest OS, select the video card in Device Manager, and upgrade its driver to the QXL XDDM one. Download location: http://www.spice-space.org/download.html, Guest | Windows binaries. This enables further resolutions at OS runtime, and provides S3 (suspend/resume) capability.
/** Locates the PEI Core entry point address @param[in,out] Fv The firmware volume to search @param[out] PeiCoreEntryPoint The entry point of the PEI Core image @retval EFI_SUCCESS The file and section was found @retval EFI_NOT_FOUND The file and section was not found @retval EFI_VOLUME_CORRUPTED The firmware volume was corrupted **/ VOID FindPeiCoreImageBase ( IN OUT EFI_FIRMWARE_VOLUME_HEADER **BootFv, OUT EFI_PHYSICAL_ADDRESS *PeiCoreImageBase ) { BOOLEAN S3Resume;
*PeiCoreImageBase = 0;
S3Resume = IsS3Resume (); if (S3Resume && !FeaturePcdGet (PcdSmmSmramRequire)) { // // A malicious runtime OS may have injected something into our previously // decoded PEI FV, but we don't care about that unless SMM/SMRAM is required. // DEBUG ((DEBUG_VERBOSE, "SEC: S3 resume\n")); GetS3ResumePeiFv (BootFv); } else { // // We're either not resuming, or resuming "securely" -- we'll decompress // both PEI FV and DXE FV from pristine flash. // DEBUG ((DEBUG_VERBOSE, "SEC: %a\n", S3Resume ? "S3 resume (with PEI decompression)" : "Normal boot")); FindMainFv (BootFv);
and if not IsS3Resume and not SMM required, VM will use S3 resume but in our situation vm go throught Normal boot.
Than locates the comparessed main firmware volume /usr/share/edk2/ovmf/OVMF_CODE.cc.fd
1 2 3 4 5 6 7 8 9 10 11 12 13
/** Locates the compressed main firmware volume and decompresses it. @param[in,out] Fv On input, the firmware volume to search On output, the decompressed BOOT/PEI FV @retval EFI_SUCCESS The file and section was found @retval EFI_NOT_FOUND The file and section was not found @retval EFI_VOLUME_CORRUPTED The firmware volume was corrupted **/ EFI_STATUS DecompressMemFvs (
Next step is still find PEI core entry address, EFI_SECTION_PE32 and EFI_SECTION_TE will be used to find entry address
/** Locates the PEI Core entry point address @param[in] Fv The firmware volume to search @param[out] PeiCoreEntryPoint The entry point of the PEI Core image @retval EFI_SUCCESS The file and section was found @retval EFI_NOT_FOUND The file and section was not found @retval EFI_VOLUME_CORRUPTED The firmware volume was corrupted **/ EFI_STATUS FindPeiCoreImageBaseInFv ( IN EFI_FIRMWARE_VOLUME_HEADER *Fv, OUT EFI_PHYSICAL_ADDRESS *PeiCoreImageBase ) { EFI_STATUS Status; EFI_COMMON_SECTION_HEADER *Section;
Status = FindFfsFileAndSection ( Fv, EFI_FV_FILETYPE_PEI_CORE, EFI_SECTION_PE32, &Section ); if (EFI_ERROR (Status)) { Status = FindFfsFileAndSection ( Fv, EFI_FV_FILETYPE_PEI_CORE, EFI_SECTION_TE, &Section ); if (EFI_ERROR (Status)) { DEBUG ((DEBUG_ERROR, "Unable to find PEI Core image\n")); return Status; } }
Back to where FindPeiCoreImageBase’s code path, we can find SecCoreStartupWithStack is the start function which is used in OvmfPkg/Sec/X64/SecEntry.nasm
// // Enable the access routines while probing to see if it is supported. // For probing we always use the IO Port (IoReadFifo8()) access method. // mQemuFwCfgSupported = TRUE; mQemuFwCfgDmaSupported = FALSE;
if ((Revision & FW_CFG_F_DMA) == 0) { DEBUG ((DEBUG_INFO, "QemuFwCfg interface (IO Port) is supported.\n")); } else { mQemuFwCfgDmaSupported = TRUE; DEBUG ((DEBUG_INFO, "QemuFwCfg interface (DMA) is supported.\n")); }
if (mQemuFwCfgDmaSupported && MemEncryptSevIsEnabled ()) { EFI_STATUS Status;
// // IoMmuDxe driver must have installed the IOMMU protocol. If we are not // able to locate the protocol then something must have gone wrong. // Status = gBS->LocateProtocol (&gEdkiiIoMmuProtocolGuid, NULL, (VOID **)&mIoMmuProtocol); if (EFI_ERROR (Status)) { DEBUG ((DEBUG_ERROR, "QemuFwCfgSevDma %a:%a Failed to locate IOMMU protocol.\n", gEfiCallerBaseName, __FUNCTION__)); ASSERT (FALSE); CpuDeadLoop (); } }
return RETURN_SUCCESS; }
because FW CFG Revision: 0x3 is supported, according to the code, Revision is > 1 so QemuFwCfg interface is supported, but from next part 0x03 & FW_CFG_F_DMA which is BIT1 0x01 is not 0 so actually QemuFwCfg interface (DMA) is supported. is expected.
1 2 3 4 5 6
if ((Revision & FW_CFG_F_DMA) == 0) { DEBUG ((DEBUG_INFO, "QemuFwCfg interface (IO Port) is supported.\n")); } else { mQemuFwCfgDmaSupported = TRUE; DEBUG ((DEBUG_INFO, "QemuFwCfg interface (DMA) is supported.\n")); }
so that means the boot is not correctly performed. But next boot still triggered so we should check how the boot can be triggered before we dig out the truth.
According to code,we can know edk2-ovmf is try to load PlatformPei.efi
1 2
Loading PEIM 222C386D-5ABC-4FB4-B124-FBB82488ACF4^M Loading PEIM at 0x00000834A40 EntryPoint=0x0000083A751 PlatformPei.efi^M
use the guid 222C386D-5ABC-4FB4-B124-FBB82488ACF4 we can easily get definitions in PlatformPei.inf
SecCoreStartupWithStack is first log when guest boot, and we end with ReadSevMsr = true but nothing after that.
Before we could see PlatformPei.efi is loading, so refer to PlatformPei.efi first. But the QemuFwCfgLib seems not successfully initialized, because the log end up during its load procedure not show Platform PEIM Loaded
1 2 3 4 5 6 7 8
EFI_STATUS EFIAPI InitializePlatform ( IN EFI_PEI_FILE_HANDLE FileHandle, IN CONST EFI_PEI_SERVICES **PeiServices ) { DEBUG ((DEBUG_INFO, "Platform PEIM Loaded\n"));
And refer to OvmfPkgX64.dsc describes c lib every procedure should use:
// // Enable the access routines while probing to see if it is supported. // For probing we always use the IO Port (IoReadFifo8()) access method. // mQemuFwCfgSupported = TRUE; mQemuFwCfgDmaSupported = FALSE;
DEBUG ((DEBUG_INFO, "check supported result: %d\n", (Revision & FW_CFG_F_DMA))); if ((Revision & FW_CFG_F_DMA) == 0) { DEBUG ((DEBUG_INFO, "QemuFwCfg interface (IO Port) is supported.\n")); } else { // // If SEV is enabled then we do not support DMA operations in PEI phase. // This is mainly because DMA in SEV guest requires using bounce buffer // (which need to allocate dynamic memory and allocating a PAGE size'd // buffer can be challenge in PEI phase) // if (MemEncryptSevIsEnabled ()) { DEBUG ((DEBUG_INFO, "SEV: QemuFwCfg fallback to IO Port interface.\n")); } else { mQemuFwCfgDmaSupported = TRUE; DEBUG ((DEBUG_INFO, "QemuFwCfg interface (DMA) is supported.\n")); } }
the code enter the MemEncryptSevIsEnabled () and hang on next function:
note: SEC_SEV_ES_WORK_AREA is a new AREA added by amd used for their SEV feature. Normally guest without SEV feature should not modify those memory area, but it seems windows write randomly bits which caused this problem.
From edk2 groups
Same issue is found https://edk2.groups.io/g/devel/topic/87301748#84086
According to the mail:
1 2 3 4 5
Tested on Intel Platform, It is like 'SEV-ES work area' can be modified by os(Windows etc), and will not restored on reboot, the SevEsWorkArea->EncryptionMask may have a random value after reboot. then it may casue fail on reboot. The msr bits already cached by mSevStatusChecked, there is no need to try cache again in PEI phase.
it seems Windows will change SEV-ES work area which will lead QemuFwCfgLib to readMsr when guest reboot, but actually for guests, normally SEV-ES is not used, so initializing failure cause the reboot infinite loop.
Apply uncrustify changes to .c/.h files in the OvmfPkg package
Cc: Andrew Fish <afish@apple.com> Cc: Leif Lindholm <leif@nuviainc.com> Cc: Michael D Kinney <michael.d.kinney@intel.com> Signed-off-by: Michael Kubacki <michael.kubacki@microsoft.com> Reviewed-by: Andrew Fish <afish@apple.com>
More information about my debug related procedure
UEFI boot procedure
Before debugging on edk2 code, check UEFI boot procedure to know more about UEFI boot.
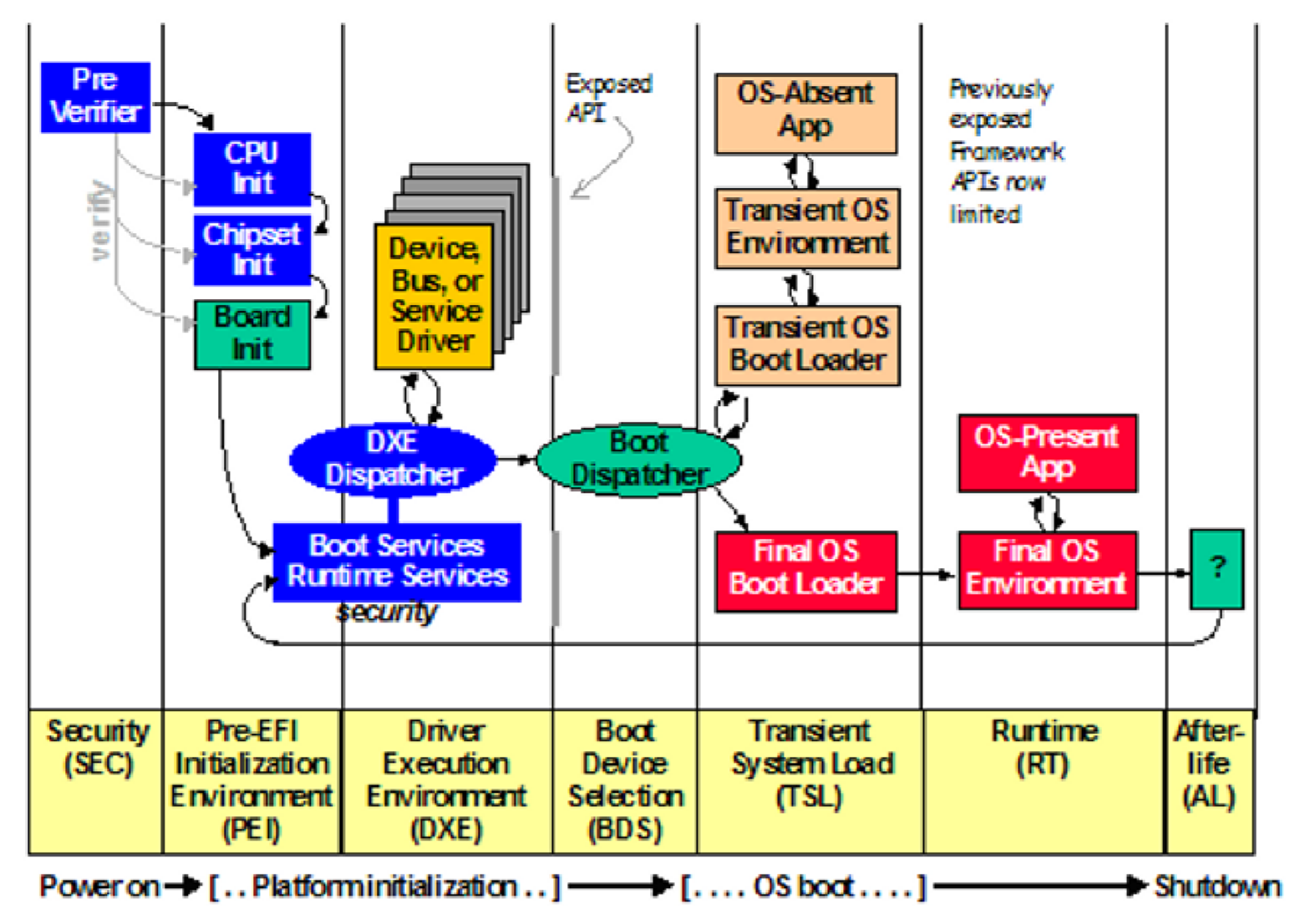
PI compliant system firmware must support the six phases: security (SEC), pre-efi initialization (PEI), driver execution environment (DXE), boot device selection (BDS), run time (RT) services and After Life (transition from the OS back to the firmware) of system. Refer to Figure below
Our issue occours at PEI so check the first two steps:
Security(SEC)
The Security (SEC) phase is the first phase in the PI Architecture and is responsible for the following:
Handling all platform restart events
Creating a temporary memory store
Serving as the root of trust in the system
Passing handoff information to the PEI Foundation
The security section may contain modules with code written in assembly. Therefore, some EDK II module development environment (MDE) modules may contain assembly code. Where this occurs, both Windows and GCC versions of assembly code are provided in different files.
Pre-EFI Initialization (PEI)
The Pre-EFI Initialization (PEI) phase described in the PI Architecture specifications is invoked quite early in the boot flow. Specifically, after some preliminary processing in the Security (SEC) phase, any machine restart event will invoke the PEI phase.
The PEI phase initially operates with the platform in a nascent state, leveraging only on-processor resources, such as the processor cache as a call stack, to dispatch Pre-EFI Initialization Modules (PEIMs). These PEIMs are responsible for the following:
Initializing some permanent memory complement
Describing the memory in Hand-Off Blocks (HOBs)
Describing the firmware volume locations in HOBs
Passing control into the Driver Execution Environment (DXE) phase
Our CI/CD system ran integration test for every pull request but suddenly it met performance issue. Usually one round of integration test need 1h but this time almost all test do not finished after 1h 20min.
After check the codebase and test on lastest release stable branch, its more likely that the system met performance issue.
Before starting trip of “dig out the root cause”, check big picture of this CI/CD system architecture.
Prepare from perf
Because integration test runs on virtual machine memory, check hypervisor’s performance might gave more details. So use perf to collect run time data for analysis.
1 2 3 4 5
git clone https://github.com/brendangregg/FlameGraph # or download it from github cd FlameGraph perf record -F 99 -a -g -- sleep 60 perf script | ./stackcollapse-perf.pl > out.perf-folded ./flamegraph.pl out.perf-folded > perf.svg
Check the flame graph
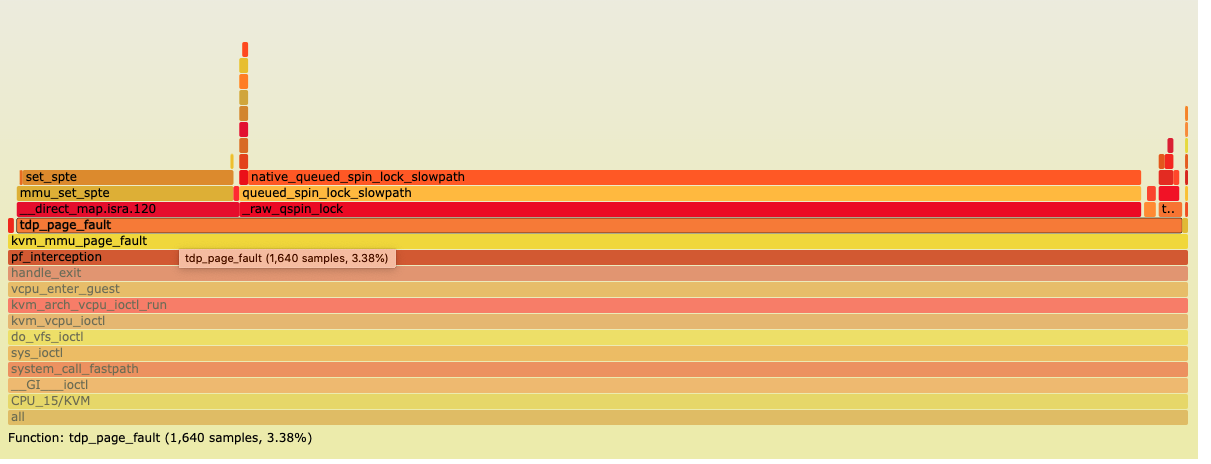
Start from tdp_page_fault
Abviously cpu spend lots of time to handle tdp_page_fault
/* * Paging state of the vcpu * * If the vcpu runs in guest mode with two level paging this still saves * the paging mode of the l1 guest. This context is always used to * handle faults. */ struct kvm_mmu mmu;
Find more by pf_interception
combine to flage graph, pf_interception is before tdp_page_fault,
Develop with libvrt python API, xml parse and operation is frequently required. ElementTree (stantard python library) is introduced in python-xml-parse come into used for the sake of simplify xml configuration lifecycle handling.
This blog will go throught xml.etree.ElementTree combine with typical situations which is use as learning notes.
First, start with some basic concepts
The Element type is a flexible container object, designed to store hierarchical data structures in memory. The type can be described as a cross between a list and a dictionary.
Each element has a number of properties associated with it:
a tag which is a string identifying what kind of data this element represents (the element type, in other words).
a number of attributes, stored in a Python dictionary.
a text string.
an optional tail string.
a number of child elements, stored in a Python sequence
Python 2.7.5 (default, Aug 4 2017, 00:39:18) [GCC 4.8.5 20150623 (Red Hat 4.8.5-16)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import xml.etree.ElementTree as ET >>> tree = ET.parse('test_data.xml') >>> root = tree.getroot() >>> root <Element 'data' at 0x7f58bd8232d0>
>>> for country in root.findall('country'): ... rank = country.find('rank').text ... name = country.get('name') ... print name, rank ... Liechtenstein 1 Singapore 4 Panama 68
use find all, all tag with name country is found and its rank text and attribute name is listed.
change the parameters for test, change findall target, test if tag not matched what will happend:
1 2 3
>>> for country in root.findall('test'): ... print country ...
when use find instead of findall
1 2 3 4 5 6 7 8
>>> for tag in root.find('country'): ... print tag ... <Element 'rank' at 0x7f58bd823f90> <Element 'year' at 0x7f58bd823fd0> <Element 'gdppc' at 0x7f58bd825050> <Element 'neighbor' at 0x7f58bd825090> <Element 'neighbor' at 0x7f58bd8250d0>
only first matched result is returned.
if find for a unexists tag None will be returned.
1 2
>>> print root.find('test') None
so in most cases, find and findall seems meet all the require for finding a specific tag.
See notation of virt/kvm/kvm_main.c in linux kernel
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* * Kernel-based Virtual Machine driver for Linux * * This module enables machines with Intel VT-x extensions to run virtual * machines without emulation or binary translation. * * Copyright (C) 2006 Qumranet, Inc. * Copyright 2010 Red Hat, Inc. and/or its affiliates. * * Authors: * Avi Kivity <avi@qumranet.com> * Yaniv Kamay <yaniv@qumranet.com> * * This work is licensed under the terms of the GNU GPL, version 2. See * the COPYING file in the top-level directory. * *
I got some questions
what means kernel-based
what is VT-x
emulation? binary traslation?
who is Avi Kivity
is there any user-mode hypervisor?
Kernel-based
Kernel-based Virtual Machine (KVM) is a virtualization module in the Linux kernel that allows the kernel to function as a hypervisor. It was merged into the mainline Linux kernel in version 2.6.20, which was released on February 5, 2007. [1]
its available under linux/virt
VT-x
1 2
This module enables machines with Intel VT-x extensions to run virtual machines without emulation or binary translation.
According to the code notation, Intel VT-x extensions is metioned.
Previously codenamed “Vanderpool”, VT-x represents Intel’s technology for virtualization on the x86 platform. On November 13, 2005, Intel released two models of Pentium 4 (Model 662 and 672) as the first Intel processors to support VT-x. The CPU flag for VT-x capability is “vmx”; in Linux, this can be checked via /proc/cpuinfo, or in macOS via sysctl machdep.cpu.features.[2]
“VMX” stands for Virtual Machine Extensions, which adds 13 new instructions: VMPTRLD, VMPTRST, VMCLEAR, VMREAD, VMWRITE, VMCALL, VMLAUNCH, VMRESUME, VMXOFF, VMXON, INVEPT, INVVPID, and VMFUNC.[21] These instructions permit entering and exiting a virtual execution mode where the guest OS perceives itself as running with full privilege (ring 0), but the host OS remains protected.[2]
note: virtual execution mode is a important concept
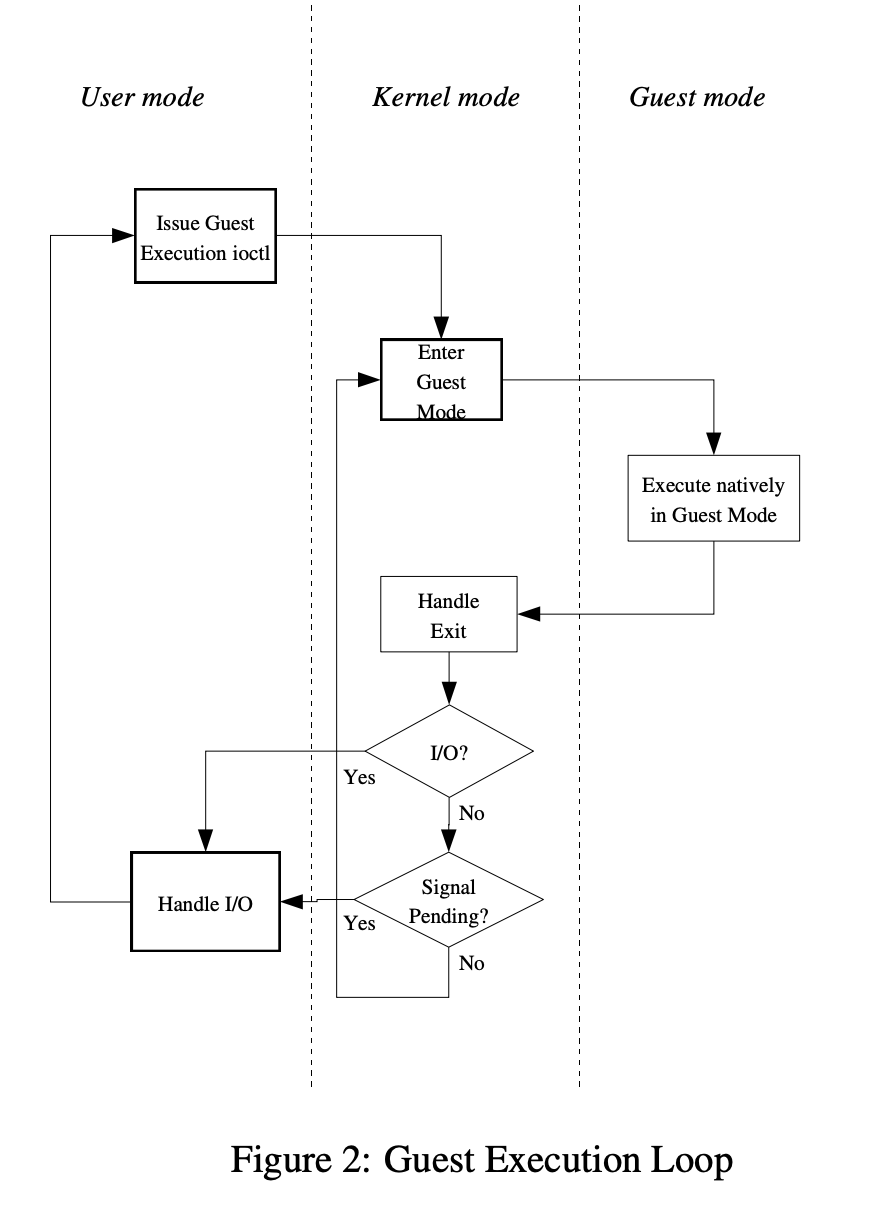
refer to paper kvm: the Linux Virtual Machine Monitor KVM is designed to add a guest mode, joining the existing kernel mode and user mode
In guest-mode CPU instruction executed natively but when I/O requests or signal(typically, network packets received or timeout), exit guest-mode is required and kvm than redirect those I/O or signal handling to user-mode process to emulation device and execute actual I/O. After I/O handling finished, KVM will enter guest mode to execute its CPU instructions again.
For kernel-mode handling exit and enter is basic task. And user-mode process calls kernel to enter guest-mode until it interrupt.
Emulation & Binary translation
In computing, binary translation is a form of binary recompilation where sequences of instructions are translated from a source instruction set to the target instruction set. In some cases such as instruction set simulation, the target instruction set may be the same as the source instruction set, providing testing and debugging features such as instruction trace, conditional breakpoints and hot spot detection.
The two main types are static and dynamic binary translation. Translation can be done in hardware (for example, by circuits in a CPU) or in software (e.g. run-time engines, static recompiler, emulators).[3]
Emulators mostly used to run softwares or applications on current OS where those softwares or applications are not support. For example, https://github.com/OpenEmu/OpenEmu a multiple video game system. This is advantage of emulators.
Disadvantage is that binary translation sometimes require instructino scan, if its used for CPU instruction translations, it spends more time than native instruction. More details in Translator-Internals will be talked in next blogs.
Avi Kivity
Mad C++ developer, proud grandfather of KVM. Now working on @ScyllaDB, an open source drop-in replacement for Cassandra that’s 10X faster. Hiring (remotes too).
Avi Kivity began the development of KVM in mid-2006 at Qumranet, a technology startup company that was acquired by Red Hat in 2008. KVM surfaced in October, 2006 and was merged into the Linux kernel mainline in kernel version 2.6.20, which was released on 5 February 2007.
KVM is maintained by Paolo Bonzini. [1]
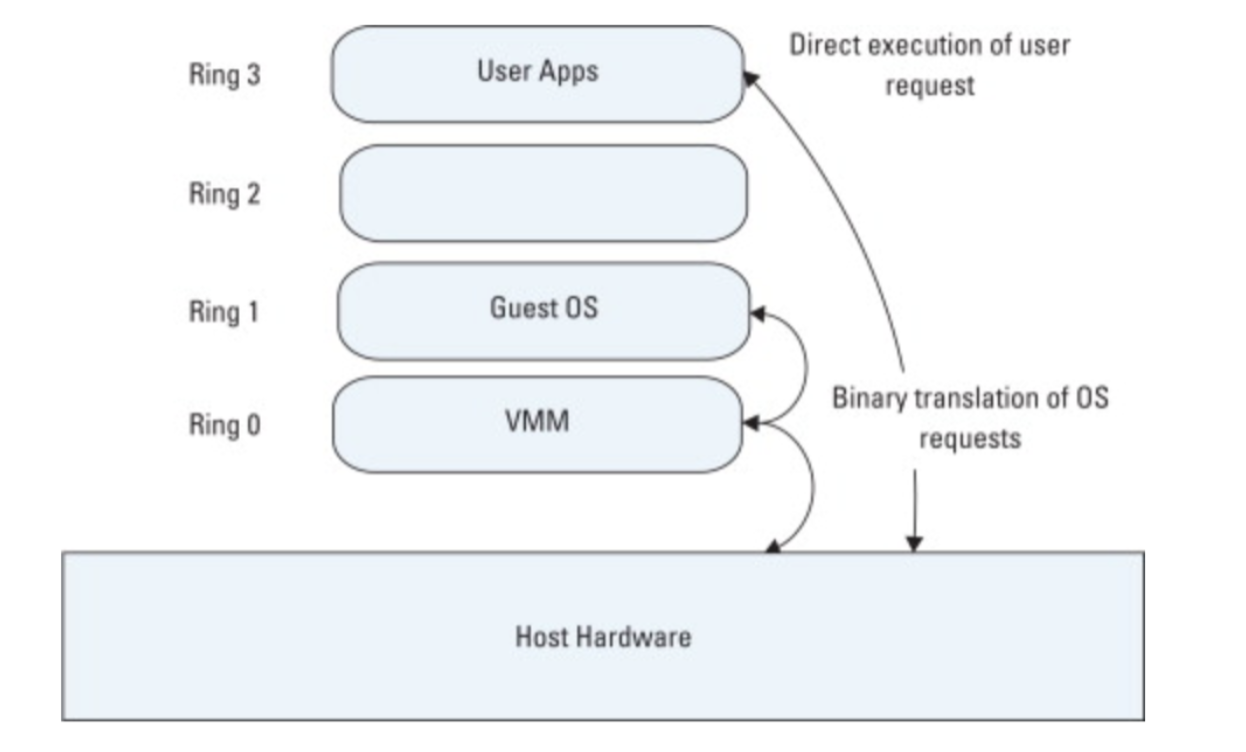
Virtualization
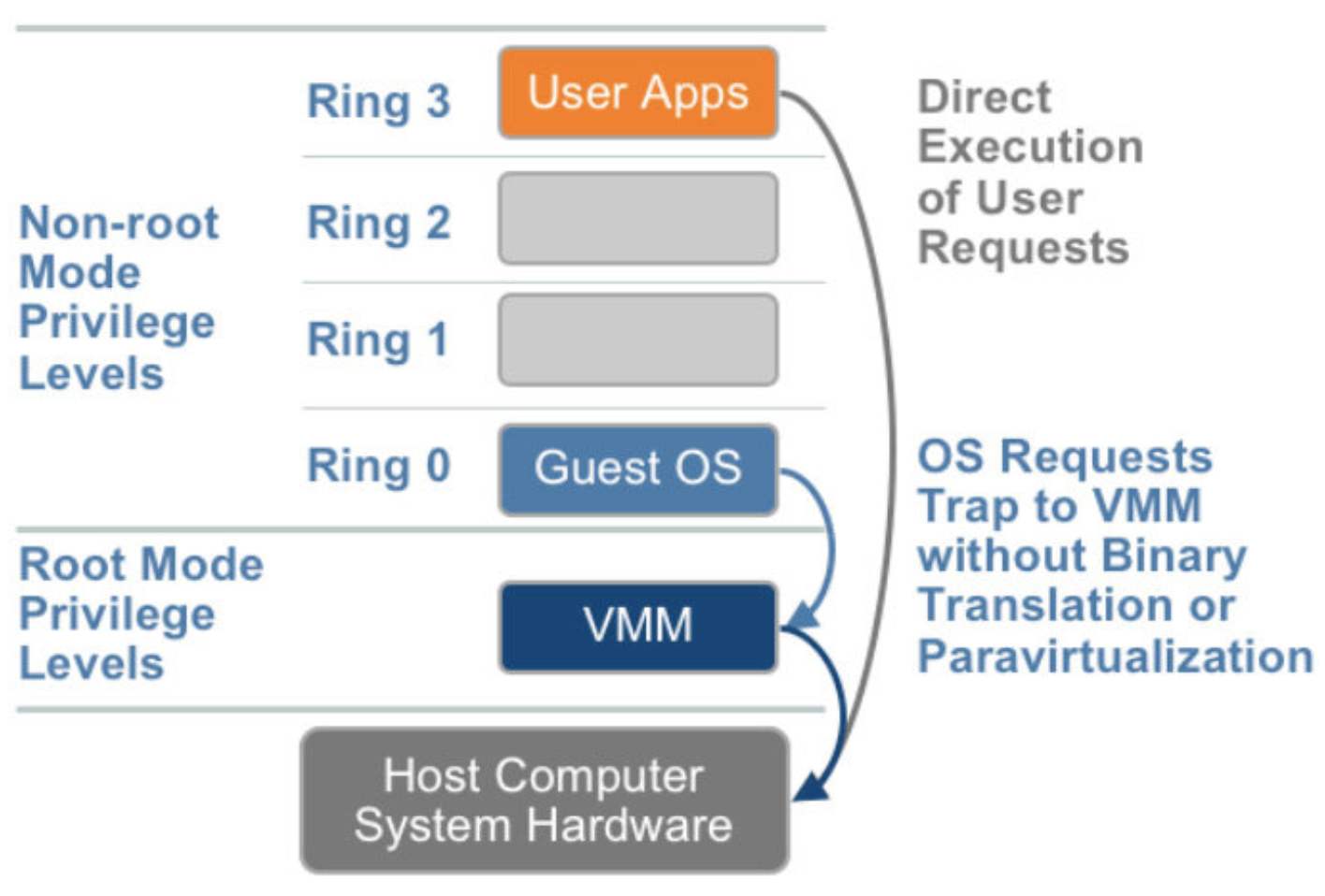
For hardware assisted virtualiztion, VMM running below ring0 Guest OS, user application can directly execute user requests, and sensitive OS call trap to VMM without binary translation or Paravirtualization so overhead is decreased.
But for older full virtualization design
Guest OS runs on Ring1 and VMM runs on Ring0, without hardware assist, OS requests trap to VMM and after binary translation the instruction finally executed.
KVM Details
Memory map
From perspective of Linux guest OS. Physical memory is already prepared and virtual memory is allocated depend on the physical memory. When guest OS require a virtual address(GVA), Guest OS need to translate is to guest physical address(GPA), this obey the prinsiple of Linux, and tlb, page cache will be involved. And no difference with a Linux Guest running on a real server.
From perspective of host, start a Guest need to allocate a memory space as GPA space. So every GPA has a mapped host virtual address(HVA) and also a host physical address(HPA)
So typically, if a guest need to access a virtual memory address
GVA -> GPA -> HVA -> GPA
at least three times of translation is needed.
Nowadays, CPU offer EPT(Intel) or NPT(AMD) to accelerate GPA -> HVA translation. We will refer that in after blogs.
vMMU
MMU consists of
A radix tree ,the page table, encoding the virtual- to-physical translation. This tree is provided by system software on physical memory, but is rooted in a hardware register (the cr3 register)
A mechanism to notify system software of missing translations (page faults)
An on-chip cache(the translation lookaside buffer, or tlb) that accelerates lookups of the page table
Instructions for switching the translation root inorder to provide independent address spaces
Instructions for managing the tlb
As referred in Memory map GPA -> HVA should be offered by KVM.
If no hardware assist, use shadow table to maintain the map between GPA and HVA, the good point of shadow table is that runtime address translation overhead is decrease but the major problem is how to synchronize guest page table with shadow page table, when guest writes page table, the shadow page table need to be changed together, so virtual MMU need offer hooks to implement this.
Another question is context switch. Shadow page tables based on the fact that guest should sync its tlb with shadow page tables so that tlb management instruction will be trapped. But the most common tlb management instruction in context-switch is invalidates the entire tlb. So the shadow page tables need to be synced again. Causes bad performance when vm runs multi processes.
vMMU is implement in order to improve guest performance which caches all page tables during context switch. This means context swtich could find its cache from vMMU directly, invdalidates tlb has no influence on context-switch.
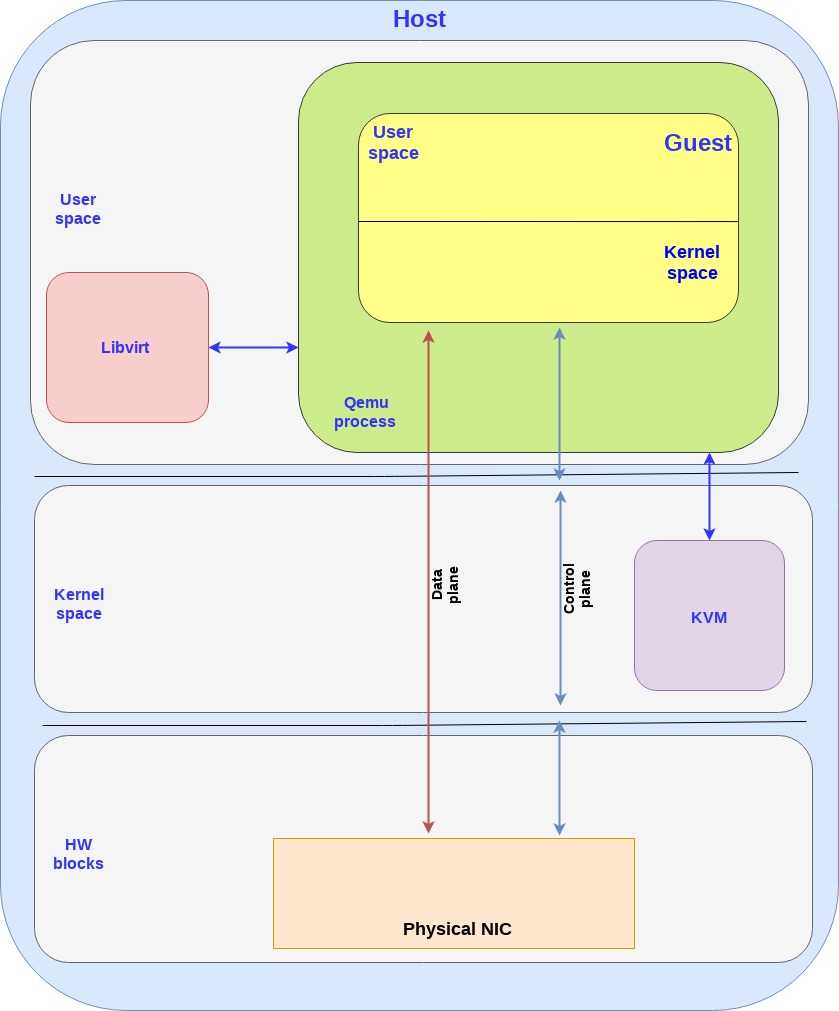
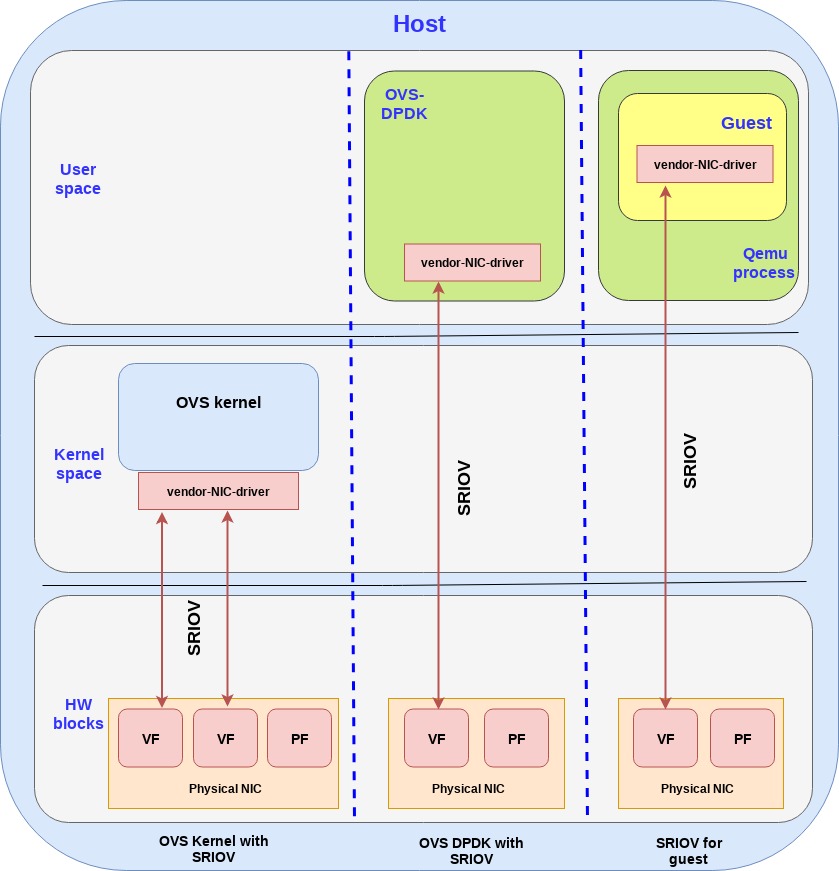
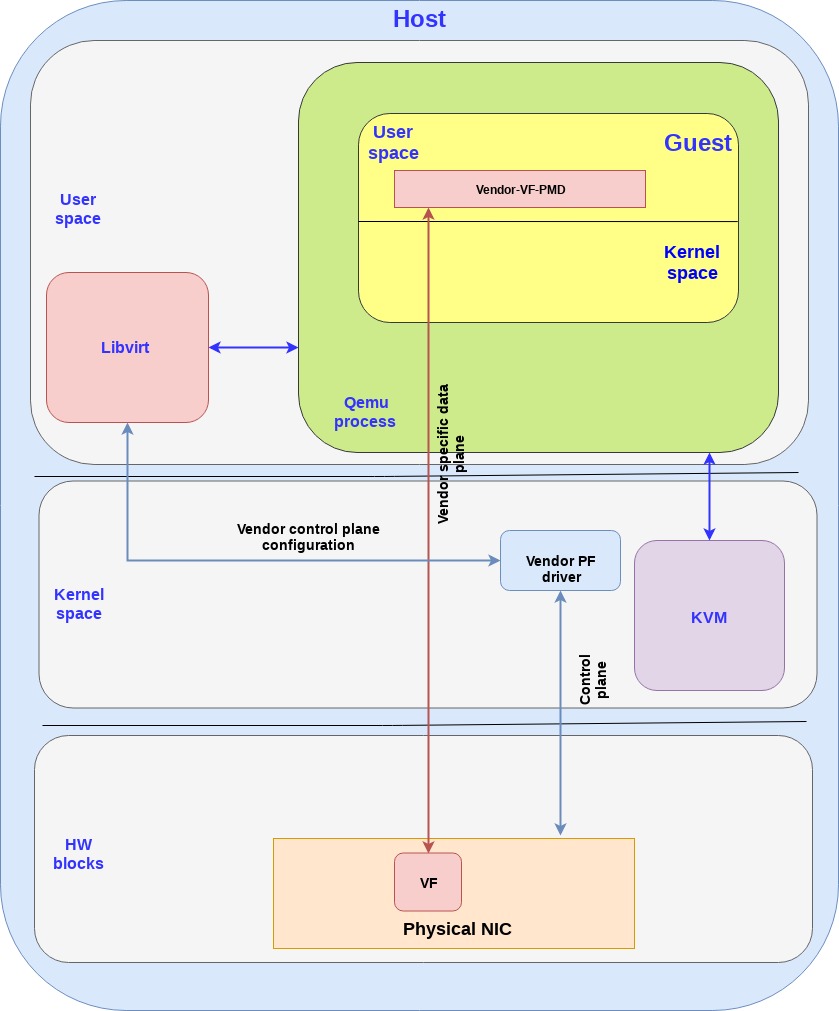
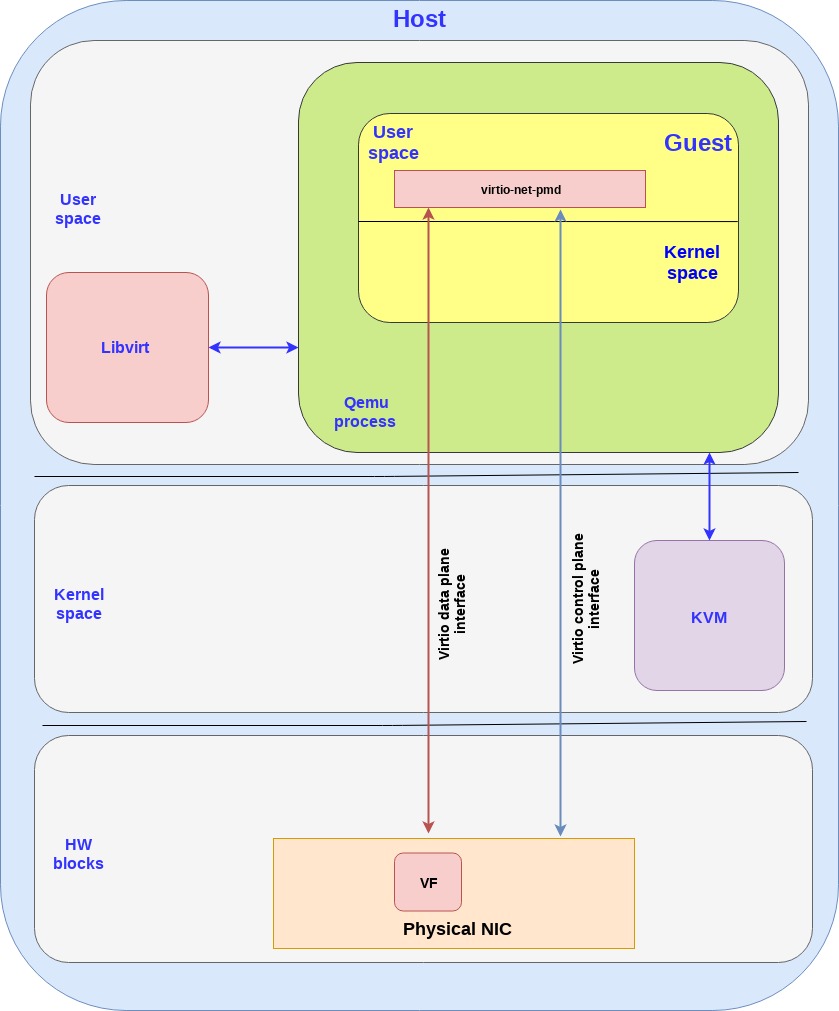
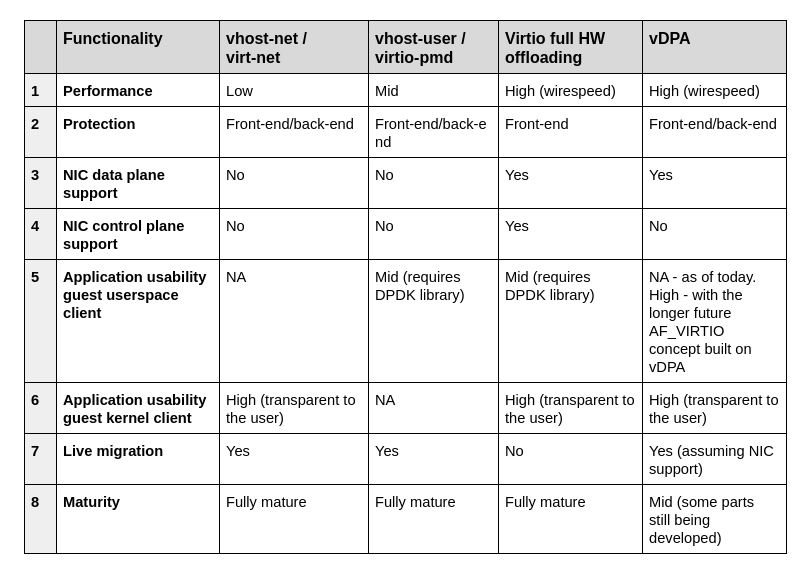
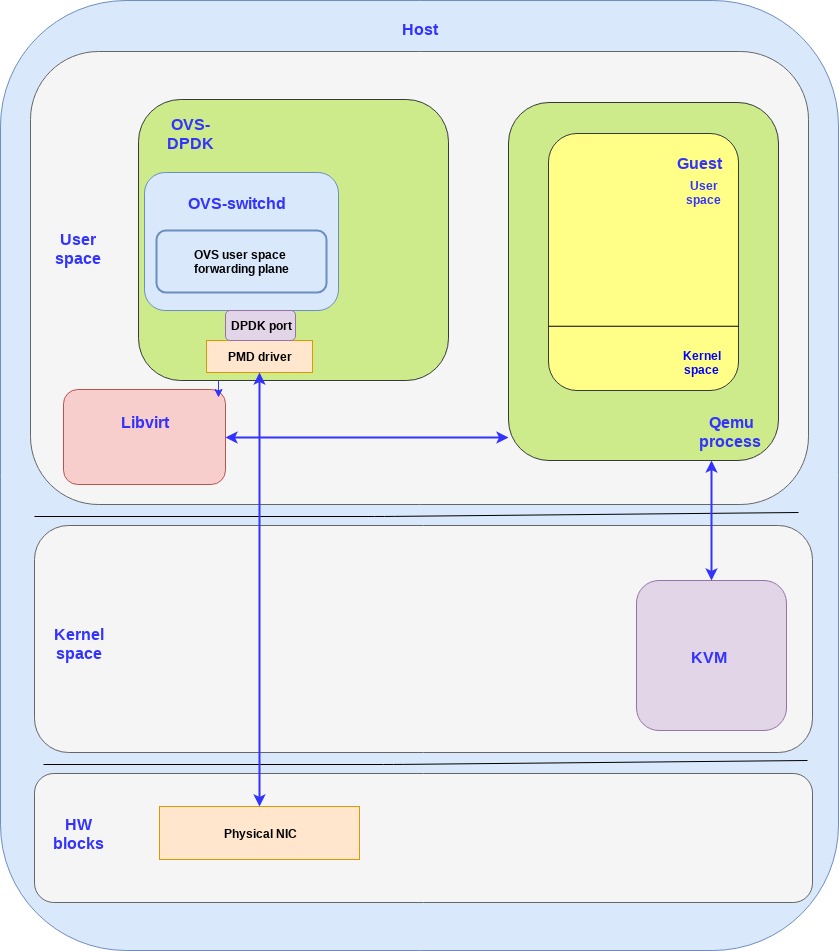
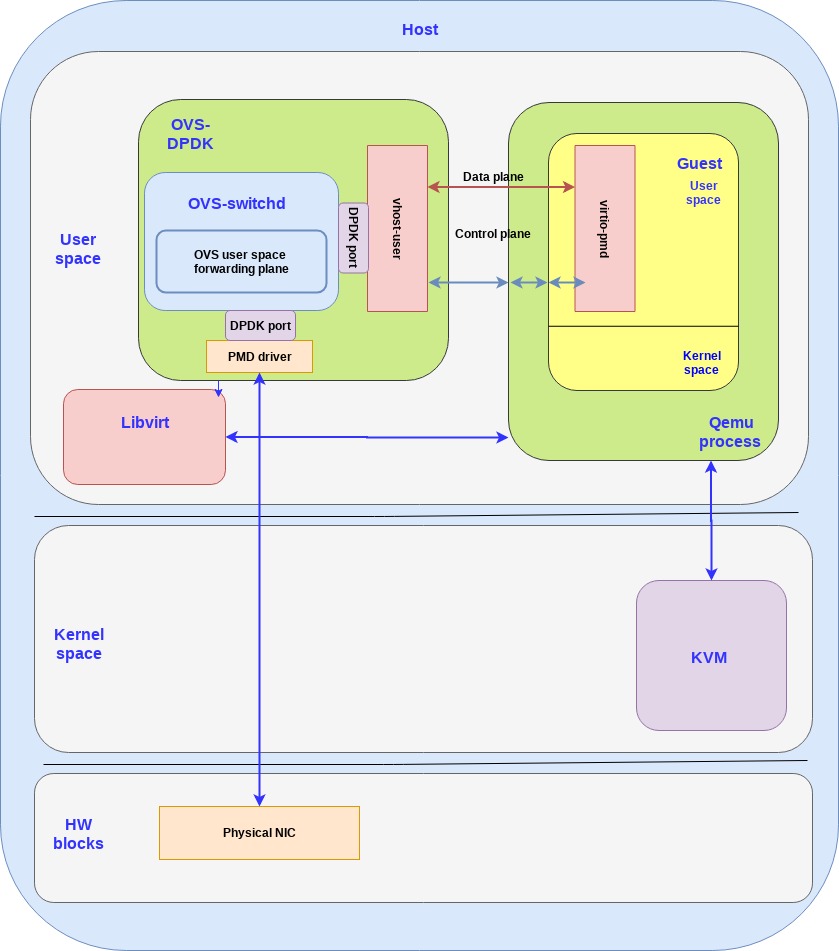
第一个方案是virtio的硬件替代方案,把virtio的控制面和数据面都转移到硬件上,也就是说网卡(当然还是通过VF来提供虚拟接口),支持virtio控制面的标准,包括发现,特性协商,以及建立/销毁数据面,等等。这个设备也支持virtio rang layout,因此一旦内存在网卡和guest之间被映射了,他们就能够直接通信了。
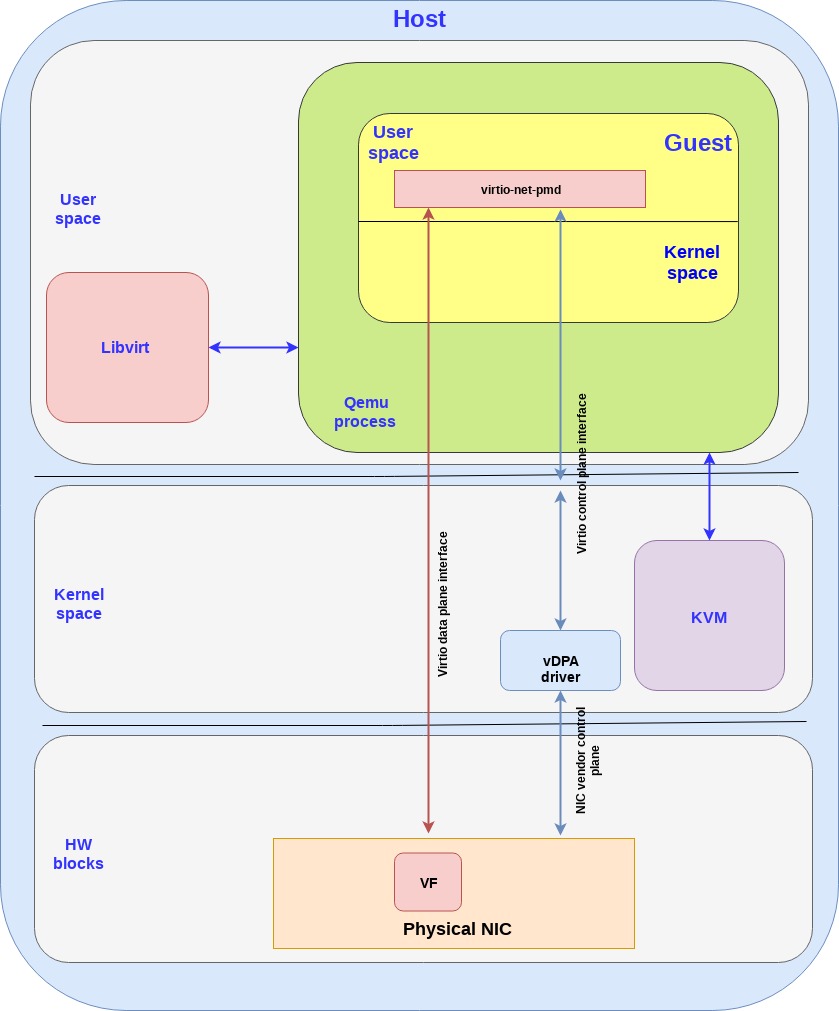
Virtual data path acceleration (vDPA) 是一个通过virtio ring layout和放置一个SRIOV在guest,来标准化网卡SRIOV数据面将这个网络性能改善和厂家实现解耦的方案,通过增加一个通用的控制面以及阮家架构来支持vDPA。提供一个抽象层,在SRIOV之上,并且给未来的可拓展IOV打好基础。
和virtio的硬件方案类似,数据面直接建立在网卡和guest之间,都使用virtio ring layout。然而每个网卡厂家可能就会提供各自的驱动了,然后一个通用的vDPA驱动就被添加到了kernel里面来完成常见网卡驱动或控制面之间的virtio控制面翻译工作。
vDPA是一个灵活性更高的方案,相比硬件方案来说,网卡厂家支持virtio ring layout的成本更小了,并且也能够达到性能提升的目的。
CPU core -> MMU(TLBs, Table Walk Unit) -> Caches -> Memory(Translation tables)
CPU VA -> MMU find PTE(Pysical table entry) -> TLB -> L1 cache -> L2 cache -> L3 cache
note: pretend a architecture with TLB between CPU and L1 cache.
TLB is a some cache form VA-to-PA translaction and formed by PTE blocks.
if TLB miss, CPU find PA from L1 and so on until PA is find and then put the PTE into TLB.
what is TLB?
TLB definition from wiki: A translation lookaside buffer (TLB) is a memory cache that is used to reduce the time taken to access a user memory location. It is a part of the chip’s memory-management unit (MMU). The TLB stores the recent translations of virtual memory to physical memory and can be called an address-translation cache. A TLB may reside between the CPU and the CPU cache, between CPU cache and the main memory or between the different levels of the multi-level cache. The majority of desktop, laptop, and server processors include one or more TLBs in the memory-management hardware, and it is nearly always present in any processor that utilizes paged or segmented virtual memory.
note:
TLB stores recent translations that means not all address translation entry is stored in TLB, take care about cache miss.
TLB may reside between the CPU and the CPU cache, between the CPU cache and primary storage memory, or between levels of a multi-level cache.
virtual addressing met cache miss or physical addressing, CPU always uses TLB to find and store it into cache.
cache strategy LRU or FIFO
The CPU has to access main memory for an instruction-cache miss, data-cache miss, or TLB miss, but compare to others the third case TLB miss is too expensive.
freqently TLB misses occur degrading performance, because each newly cached page displacing one that will soon be used again. Where the TLB acting as a cache for the memory management unit (MMU) which translates virtual addresses to physical addresses is too small for the working set of pages. TLB thrashing can occur even if instruction cache or data cache thrashing are not occurring, because these are cached in different sizes. Instructions and data are cached in small blocks (cache lines), not entire pages, but address lookup is done at the page level. Thus even if the code and data working sets fit into cache, if the working sets are fragmented across many pages, the virtual address working set may not fit into TLB, causing TLB thrashing.
TLB-miss handling
Two schemes for handling TLB misses are commonly found in modern architectures:
With hardware TLB management, the CPU automatically walks the page tables . On x86 for example, use CR3 register to walks page tables if entry exists, bring back to TLB and TLB tries and access will hit. Or raise a page fault exception which need to be handled by operation system and load correct physical address to TLB(page swap in/out). CPU change do not cause loss of compatibility for the programs.
With software-managed TLBs, a TLB miss generates a TLB miss exception, and operating system code is responsible for walking the page tables and performing the translation in software. The operating system then loads the translation into the TLB and restarts the program from the instruction that caused the TLB miss. As with hardware TLB management, if the OS finds no valid translation in the page tables, a page fault has occurred, and the OS must handle it accordingly. Instruction sets of CPUs that have software-managed TLBs have instructions that allow loading entries into any slot in the TLB. The format of the TLB entry is defined as a part of the instruction set architecture (ISA).
note:
hardware TLB management TLB handling the lifecycle of TLB entries.
hardware TLB management throws page fault that OS must handling and OS should bring the missing table entry of physical address into TLB cache. And than the program resume.
hardware TLB management maintain TLB enties is invisible to software.
hardware TLB management can change from CPU to CPU, but without causing compatibility for the programs. In other words, CPU should obey the rules of TLB management so there is always any page fault exception require OS to handle
software TLB management throws TLB miss exception and OS owns the responsibility to walk page tables and translation in software. Then OS loads TLB table and restart programs (attention! not resume but restart).
compare hardware and software TLB management, according to 2 CPU finds TLB and throw page fault exception when hardware, but in sofware situation, the CPU’s instruction sets should have instruction to load TLB to anywhere and TLB entry can be used directly by CPU instruction
In most cases, hardware TLB management is used. But according to wiki, some of the architectures using software TLB management.
Typical TLB
These are typical performance levels of a TLB:
Size: 12 bits – 4,096 entries
Hit time: 0.5 – 1 clock cycle
Miss penalty: 10 – 100 clock cycles
Miss rate: 0.01 – 1% (20–40% for sparse/graph applications)
The average effective memory cycle rate is defined as m + (1-p)h + pm cycles, where m is the number of cycles required for a memory read, p is the miss rate, and h is the hit time in cycles. If a TLB hit takes 1 clock cycle, a miss takes 30 clock cycles, a memory read takes 30 clock cycles, and the miss rate is 1%, the effective memory cycle rate is an average of 30 + 0.99 * 1 + 0.01 * 30 (31.29 clock cycles per memory access)
note: research more of TLB performance
use perf test TLB miss
1
perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses -p $PID
if a high TLB missing rate exists in your OS, try to use huge page to decrease the table entries in TLB which will cut down the miss rate. But some application is not siutable for huge page and more details need to be change before use this solution.
Address-space switch
After process context switches, some TLB entries’ virtual address to physical address mapping is invalid. In order to clean thoes invalid entires, some strategies is required.
flush all entries after process context change
mark the entries with its process so the process context change do not matter
some architecture use a sinlge address space operating system, all process use the same virtual-to-pysical mapping
some CPU have a process register and hardware uses TLB entries only the current process ID matches
note: flushing TLB is an important security mechanism for memory isolation. Memory isolation is especially critical during switches between the privileged operating system kernel process and the user processes – as was highlighted by the Meltdown security vulnerability[2]. Mitigation strategies such as kernel page-table isolation (KPTI) rely heavily on performance-impacting TLB flushes and benefit greatly from hardware-enabled selective TLB entry management such as PCID.
Virtualization and x86 TLB
With the advent of virtualization for server consolidation, a lot of effort has gone into making the x86 architecture easier to virtualize and to ensure better performance of virtual machines on x86 hardware
[root@localhost ~]# dpdk-devbind -b vfio-pci 0000:00:08.0 0000:00:09.0 [ 360.862724] iommu: Adding device 0000:00:08.0 to group 0 [ 360.871147] vfio-pci 0000:00:08.0: Adding kernel taint for vfio-noiommu group on device [ 360.951240] iommu: Adding device 0000:00:09.0 to group 1 [ 360.960126] vfio-pci 0000:00:09.0: Adding kernel taint for vfio-noiommu group on device
Port 1: link state change event VHOST_CONFIG: vring base idx:0 file:0 VHOST_CONFIG: read message VHOST_USER_GET_VRING_BASE VHOST_CONFIG: vring base idx:1 file:0 VHOST_CONFIG: read message VHOST_USER_GET_VRING_BASE
Port 0: link state change event VHOST_CONFIG: vring base idx:0 file:0 VHOST_CONFIG: read message VHOST_USER_GET_VRING_BASE VHOST_CONFIG: vring base idx:1 file:0
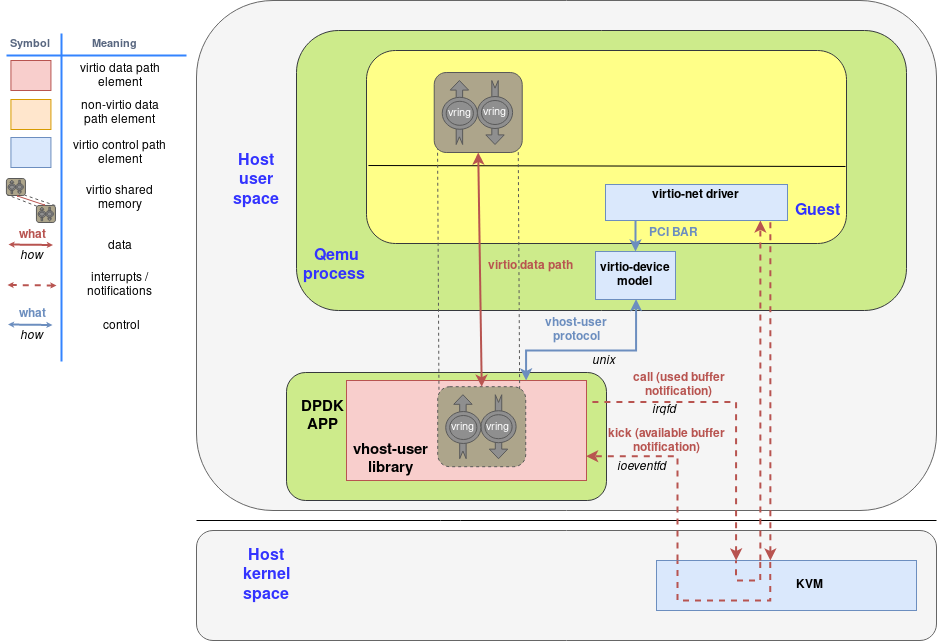
一堆eventft类的文件描述符,允许guest不通过primary直接发送和接受handler的消息:Available Buffer Notification (从guest发送到handler同志有buffers可以被处理了)和 the Used Buffer Notification (从handler发送到guest说明buffers的处理解释了)
模拟virtio设备,在guest里面展示的i一个特定的PCI端口,并且可以被guest查询和完整配置。同时他会把ioeventfd映射到模拟设备的内存映射I/O空间,同时把irqfd映射到Global System Interrupt(GSI)。结果就是,guest对这些东西时没有感知的,通知和中断都会被转发到vhost-user库而没有qemu参与。
VFIO是Virtual Function I/O的缩写。然而,Alex Williamson,vfio-pci kernel驱动的maintainer建议叫它 “Versatile Framework for userspace I/O”,这是一个更加准确的名字。VFIO是一个构建用户态驱动的基础框架,它提供了:
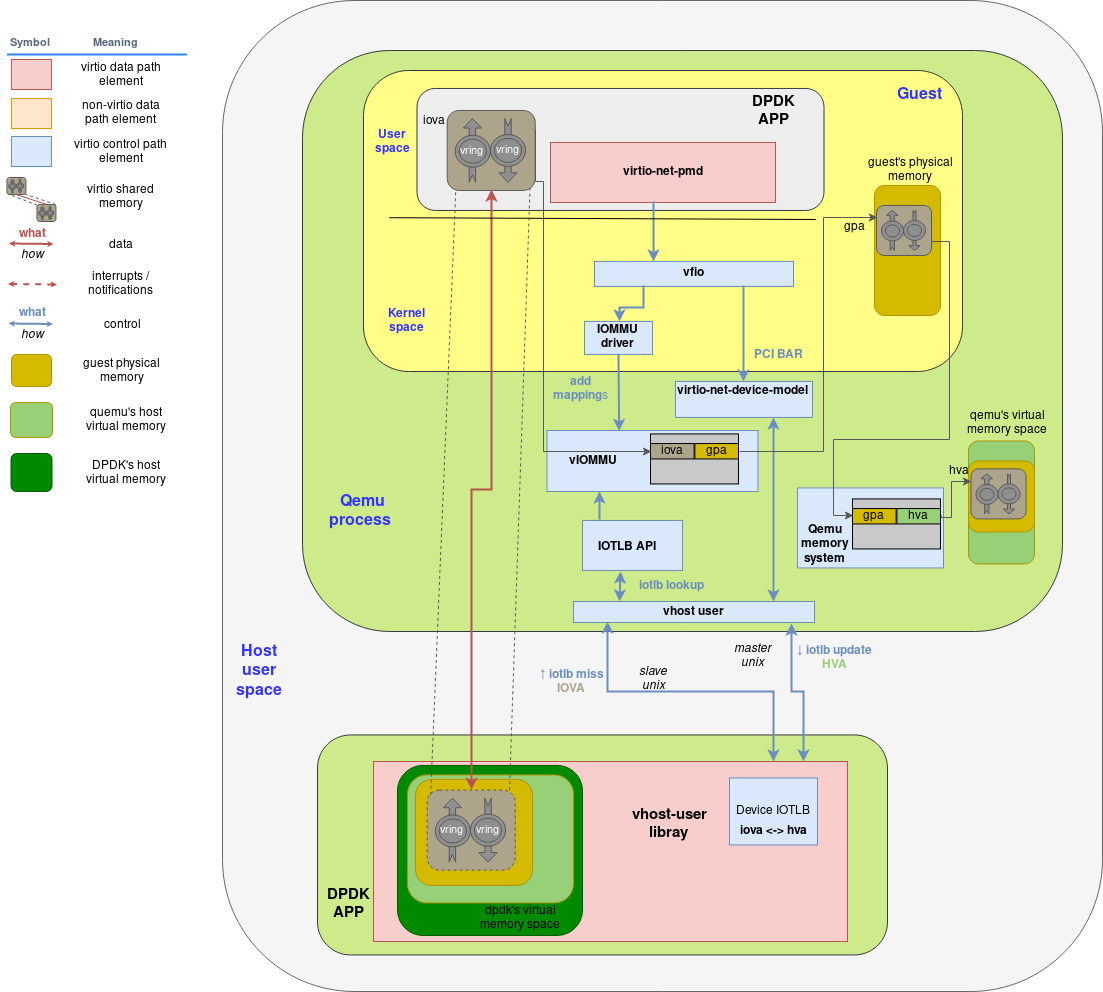
当DPDK在guest里启动的时候有以下步骤 a. 初始化PCI-vfio设备,同时映射PCI配置空间到用户内存 b. 分配virtqueue c. 使用vfio,DMA映射virtqueue内存空间,这样通过IOMMU内核驱动dma映射到vIOMMU设备 d. 然后,virto特性协商就开始了。本场景里,使用的virtqueue的地址是IOVA(在I/O虚拟内存空间)。映射eventfd和irqfd也完成了,因此中断和通知就被直接路由在guest和vhost-user库之间,而没有QEMU参与 e. 最后,DPDK应用分配一个大片的连续内存作为网络buffer。这部分映射也通过VFIO和IOMMU驱动添加到vIOMMU
[root@host ~]# virsh net-define /usr/share/libvirt/networks/default.xml Network default defined from /usr/share/libvirt/networks/default.xml [root@host ~]# virsh net-start default Network default started [root@host ~]# virsh net-list Name State Autostart Persistent -------------------------------------------- default active no yes
[root@localhost ~]# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 02:ca:fe:fa:ce:01 brd ff:ff:ff:ff:ff:ff Inspecting the host
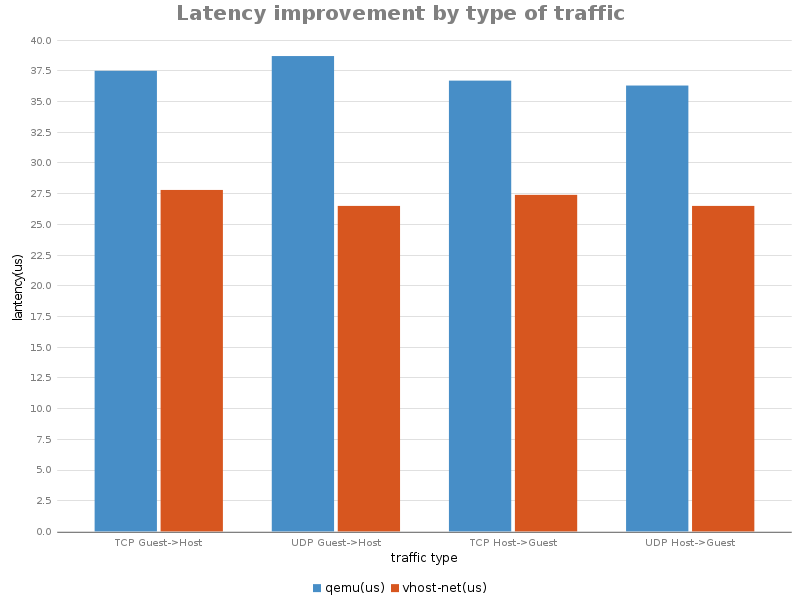
在这篇文章里面我们完整了提供了一个创建一个QEMU + vhost-net的虚拟机,检查guest和host来理解这个架构的输入输出。我们也展示了性能是如何变化的。这个系列也到此为止。从 Introduction to virtio-networking and vhost-net 的总览到技术视角深入理解的 Deep dive into Virtio-networking and vhost-net 详细的解释了这些组件,现在展示完了如果配置,希望这些内容呢能够提供足够的资源给IT专家,架构师以及研发人员理解这个技术并开始和他一起工作。