qemu quorum block filter
Based on the code design of blkverify.c and blkmirror.c, the main purpose is to mirror write requests to all the qcow images hanging in the quorum, and the read operation is to check whether the number of occurrences of the qiov version meets the value set by the threshold through the parameters set by the threshold. Then it returns the > value of the result with the highest number of occurrences, if the number of occurrences i is less than the threshold then it returns the quourm exception and the read operation returns -EIO.
The main use of this feature is for people who use NFS devices affected by bitflip errors.
If you set the read-pattern to FIFO and set the threshold to 1, you can construct a read-only first disk scenario.
block-replication
The micro checkpoint and COLO mentioned in the introduction to the QEMU FT solution will continuously create checkpoints, and the state of the pvm and svm will be the same at the moment the checkpoint is completed. But it will not be consistent until the next checkpoint.
To ensure consistency, the SVM changes need to be cached and discarded at the next checkpoint. To reduce the stress of network transfers between checkpoints, changes on the PVM disk are synchronized asynchronously to the SVM node.
For example, the first time VM1 does a checkpoint, it is recorded as state C1, then VM2’s state is also C1, at this time VM2’s disk changes start to cache, VM1’s changes are written to VM2’s node through this mechanism, if an error occurs at this time how should it be handled?
Suppose we discuss the simplest case of VM1 hanging, then because the next checkpoint has not yet been executed, VM2 continues to run the state of C1 for a period of time and the disk changes are cached, at this time it is only necessary to flush the cached data to VM2’s disk single point to continue to run or wait for FT reconstruction, which is the reason for the need to do SVM disk changes caching (here the data (including two copies, one is to restore to VM2 last checkpoint cache, the other is to VM2 in C1 after the cache of changes)
The following is the structure of block-replication:
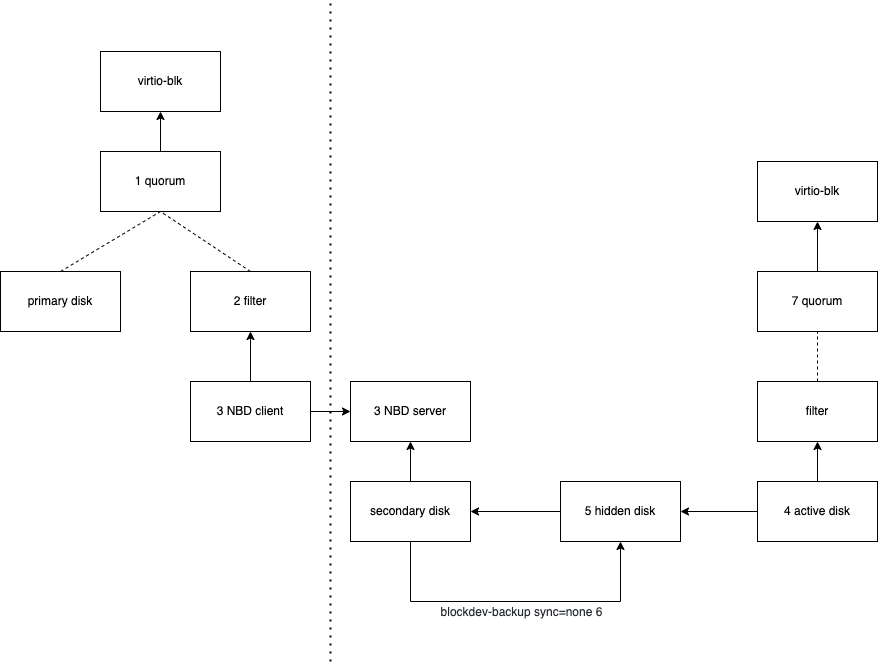
- The block device on the primary node mounts two sub-devices via quorum, providing backup from the primary node to the secondary host. The read pattern (FIFO) is extended to meet the situation where the primary node will only read the local disk (the threshold needs to be set to 1 so that read operations will only be performed locally)
- A newly implemented filter called replication is responsible for controlling block replication
- The secondary node receives disk write requests from the primary node through the embedded nbd server
- The device on the secondary node is a custom block device, we call it an active disk. it should be an empty device at the beginning, but the block device needs to support bdrv_make_empty() and backing_file
- The hidden-disk is created automatically, and this file caches the contents modified by what is written from the primary node. It should also be an empty device at the beginning and support bdrv_make_empty() and backing_file
- The blockdev-backup job (sync=none) will synchronize all the contents of the hidden-disk cache that should have been overwritten by nbd-induced writes, so the primary and secondary nodes should have the same disk contents before the replication starts
- The secondary node also has a quorum node, so that the secondary can become the new primary after the failover and continue to perform the replication
There are seven types of internal errors that can exist when block replication runs:
- Primary disk I/O errors
- Primary disk forwarding errors
- blockdev-backup error
- secondary disk I/O errors
- active disk I/O error
- Error clearing hidden disk and active disk
- failover failure
For error 1 and error 5, just report block level errors directly upwards.
For 2, 3, 4, and 6 need to be reported to the control plane of FT for failover process control.
In the case of 7, if the active commit fails, it will prompt a secondary node write operation error and let the person performing the failover decide how to handle it.
colo checkpoint
colo uses vm’s live migration to achieve the checkpoint function
Based on the above block-replication to achieve disk synchronization, the other part is how to synchronize the running state data of virtual machines, here directly using the existing live migration, that is, cloud host hot migration, so that after each checkpoint can be considered pvm and svm disk/memory are consistent, so need to be in This event depends on the time of live migration.
First, let’s organize the checkpoint process, which is divided into two major parts
Configuration phase
This part will be executed mainly when the colo is first set up, we know that by default at the beginning we will configure the disk synchronization of pvm and svm, but the memory is not actually synchronized yet, so at the beginning we will ask the svm to be pused at first after the startup, and then submit two synchronization operations from the pvm side
- Submit the drive-mirror task to mirror the contents of the disk from the pvm to the remote svm’s disk (embedded nbd is used here, which is also the target disk of the block replicaton later) to ensure that the pvm’s contents are consistent with the svm’s
- Submit a migration task to synchronize memory from pvm to svm, and since both pvm and svm are required to be paired at this point, you actually wait until both pvm and svm are synchronized, then you need to cancel the drive-mirror task, start block replication, and continue running vm
Of course, the paused state mentioned in 2 has been changed to be similar to hot migration after the improvements made by intel. After the drive-mirror task is submitted, the id of the task and the information of the block replication disks are used as parameters for the colo migration, which will actually be automatically changed when migrating in the line of online migration. After the migration is completed, the drive-mirror task is automatically cancelled and block-replication is automatically started before running vm, which simplifies the steps a lot.
After the configuration, you need to manually issue a migrate command to the colo pvm, and the checkpoint will enter the cycle of monitoring after the first migrate.
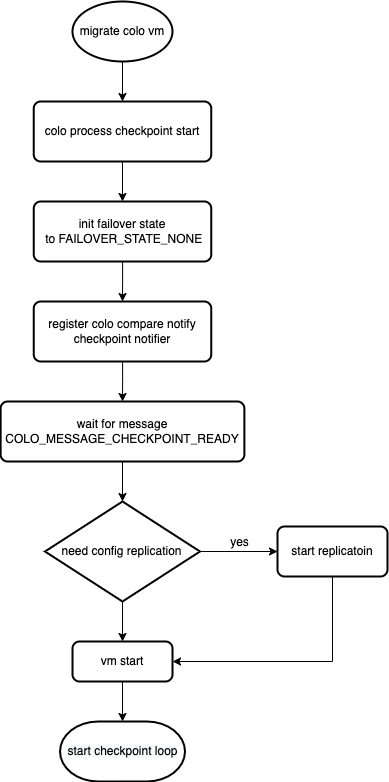
Start the checkpoint
The checkpoint mechanism consists mainly of a loop, and the code flow of qemu is as follows:
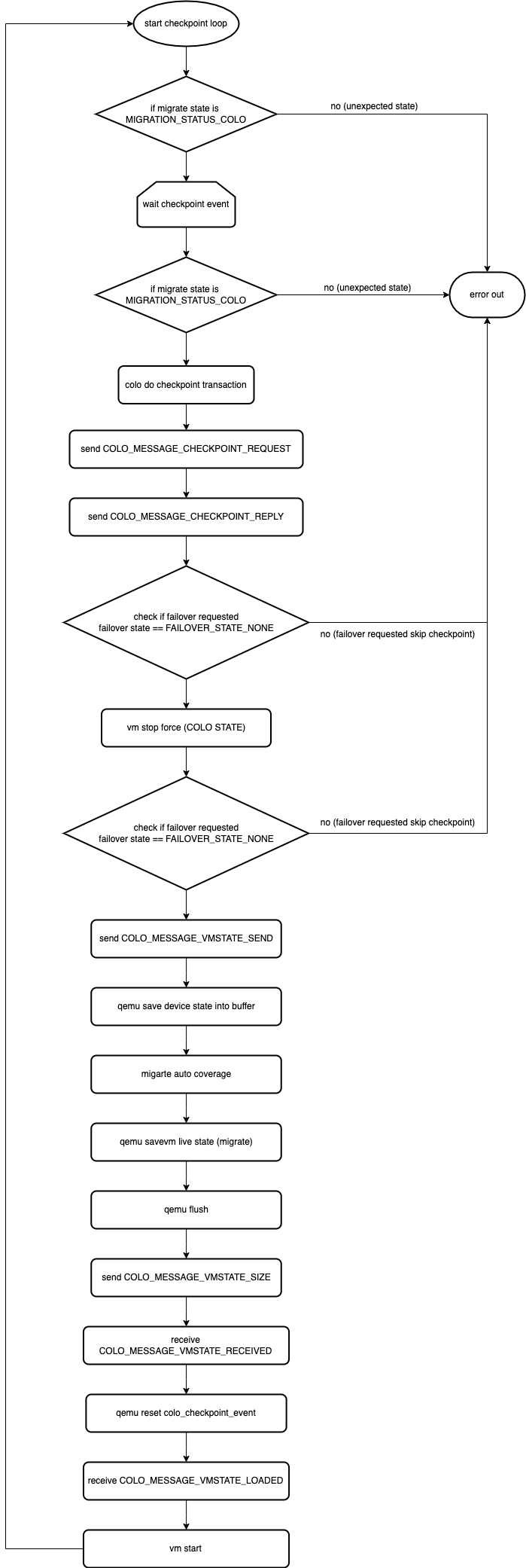
Combined with this picture we explain the more important parts inside
Process phase
COLO-FT initializes some key variables such as migration status, FAILOVER status and listens to the internal checkpoint notify (triggered from COLO compare)
After the first successful migrate, the discount state is initialized and the migration state is changed to COLO
After receiving a request for a checkpoint, a series of checkpoint creation processes are performed
Colo Status
For the COLO-FT virtual machine, there are two important states
One is the MigrationState, which on the COLO-FT virtual machine is MIGRATION_STATUS_COLO corresponding to the string “COLO”, which is a prerequisite state to allow checkpointing, and the cloud host must have established the COLO-FT mechanism. FT mechanism, that is, through the above configuration phase to complete the configuration and the first checkpoint, will enter this state and the main loop
Another state is failover_state, which is a global variable defined in colo_failover.c, which is accessed by colo.c through failover_get_state(), and this parameter is set to FAILOVER_STATUS at the start of the checkpoint loop _NONE, which means that failover is not needed. The bottom half of qemu mounts the mechanism for modifying this state, so it can be triggered by user state commands, so you need to pay attention to whether failover is triggered or not when actually doing checkpoint
Communitaion
COLO communicates through messages to get the status of the SVM, as well as to send and confirm the start and completion of the checkpoint, and the message process inside has the following main steps
- Sending COLO_MESSAGE_CHECKPOINT_REQUEST
- After the SVM receives the message, pause the SVM and send COLO_MESSAGE_CHECKPOINT_READY
- PVM starts saving and live migration of VMSTATE
- SVM gets the migrated information and does the CPU synchronization and VM state LOAD locally.
- SVM will wait for a check message from PVM after the migration is completed, and PVM will send a message after the live migration is completed.
- PVM sends COLO_MESSAGE_VMSTATE_SIZE with the size of VMSTATE sent via QIOChannelBuffer
- SVM receives the message and checks if the size received locally is the same as the size sent, if it is, it replies COLO_MESSAGE_VMSTATE_RECEIVED
- After confirming the VMSTATE transfer, the SVM will do some migration and subsequent synchronization and cleanup.
- After completion, the SVM executes vm_start() and sends COLO_MESSAGE_VMSTATE_LOADED.
- After the PVM receives the message that the SVM has successfully loaded, the PVM will also execute vm_start().
The logic of suspend, migrate and resume the operation of PVM SVM is realized through the message collaboration between PVM and SVM
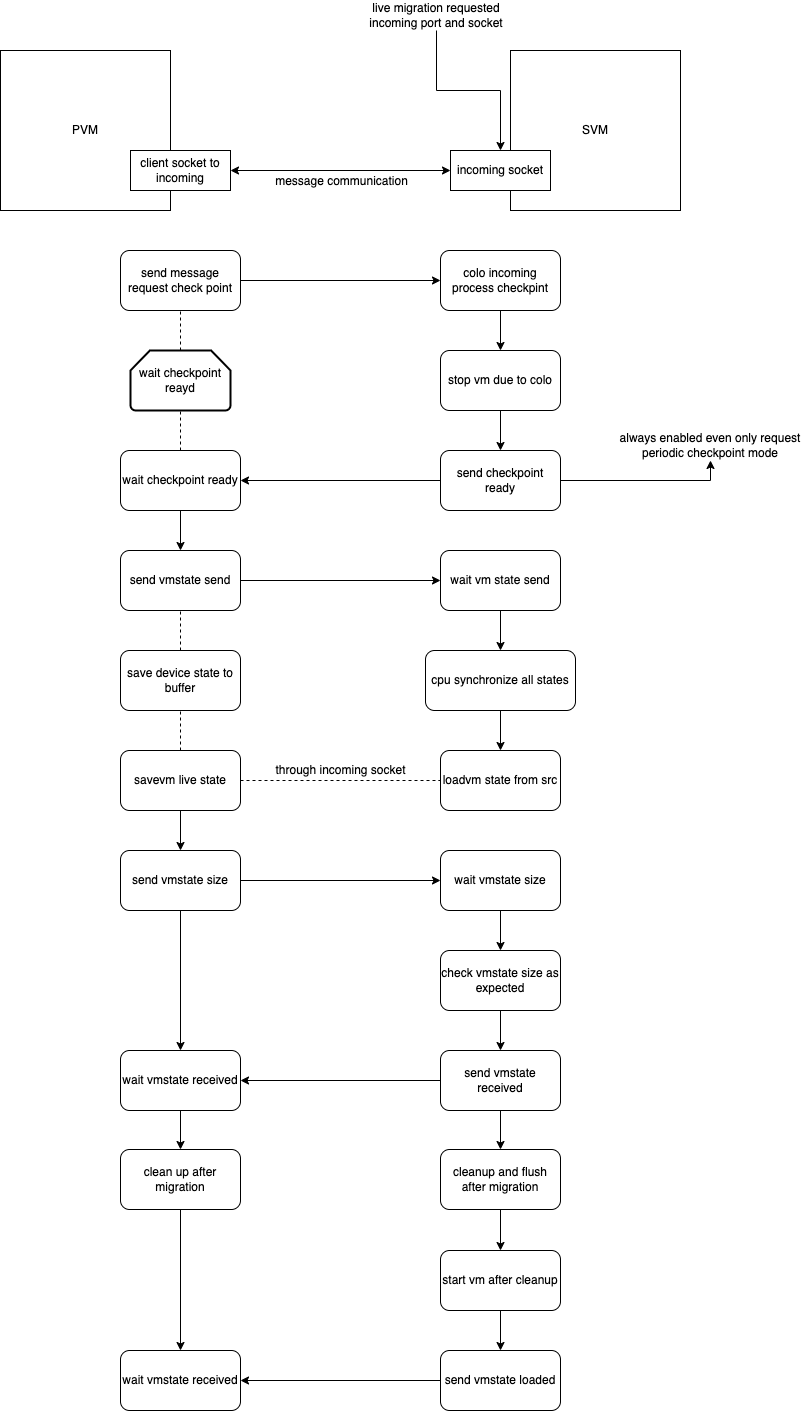
Existing problems, because the current checkpoint are notified to each other through the message, once the corresponding packet is sent and not returned, the next wait may always exist, can not be closed, assuming that at this time from the bottom half (bottom half) to send a request also did not do to clean up the wait state.
It should be noted that: the default checkpoint once the failure occurs, the vm will be a direct exit, requiring the rebuilding of COLO-FT, so the establishment of COLO-FT failure needs to be analyzed from two parts
Whether the configuration phase migration has failed
Whether the configuration is complete (migration has become colo state) but the checkpoint failed (the above process failed) resulting in COLO-FT exit
colo proxy
colo proxy as the core component of COLO-FT, this article mainly focuses on the functionality of colo proxy in QEMU
When QEMU implements the net module, it actually treats the actual device in the guest as a receiver, so the corresponding relationship is as follows
TX RX
qemu side network device (sender) ——————-→ guest inside driver (receiver)
Combined with the code, the filter will be executed before actually doing transimission, and then go to sender processing.
1 | NetQueue *queue; |
The filter-mirror and filter-redirect in the network-filter implemented by colo act as the forwarding function of the proxy
The classic process for a network card is as follows:
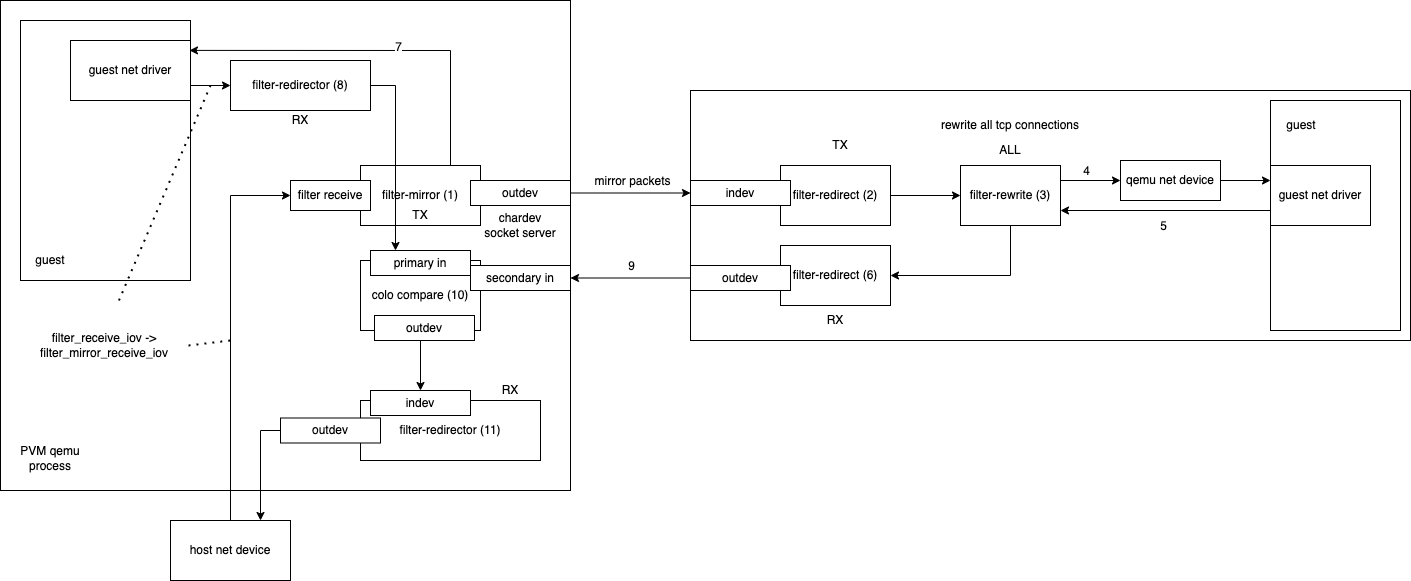
The host device receives the network packet and sends it to the guest
- First execute the first filter-mirror, for qemu is transimission, so execute mirror action, the network packet mirror a copy sent off through outdev (chardev), and then call the next filter (because it is TX, so other filters will not be executed, so pvm on (the packet is sent directly to the guest)
- SVM’s indev connects to PVM’s mirror’s outdev (via socket), so it receives the packet sent by 1. The filter does not specify an outdev after receiving the packet, so it calls the next filter directly
- SVM calls filter-rewrite, the direction of this filter is ALL, so the packets to and from SVM will be processed by this filter, if the target is sent, because it is sent to VM so the first direction is TX, COLO will record the various states of this TCP packet
- Because there is no next filter so it is sent to the qemu network device, and then take the process of sending to the guest
- From the guest to the qemu network packet, the direction is RX so the filter processing order will be reversed and sent to the rewrite first
- SVM calls filter-rewrite this time in the direction of RX, so when processing, it will process the tcp packets returned by SVM, compare the input and output of tcp packets through the tcp packets table, and if the processing fails, it will put the packet in the queue and resend it again (note: need to continue deeper analysis), and then the filter- redirector
- Also in the PVM mirror filter, because there is no subsequent TX filter, the packet is sent directly to the qemu net device and then to the PVM guest.
- The packets coming out of the PVM guest will be sent to the primary in interface of the colo-compare thing by filter-redirector because it is in the RX direction, so some filters will be performed in the reverse direction
- SVM will send the return of SVM to the secondary in interface of colo-compare of PVM via redirector’s outdev
colo-compare receives the packet and starts to do the relevant analysis to decide whether checkpoint is needed - The filter-redirector’s indev receives the return from colo-compare after comparison and forwards it to the host net device via outdev
This is the end of a complete packet processing process.
Since colo-compare is responsible for comparing pvm and svm packets, there are some metrics that need to be understood
payload
payload_size = total size - header_size i.e. the size of the whole packet minus the length of the header
packet data offset packet header size after the distance and payload_size comparison is consistent
The following is a summary of what needs to be done here
The logic of colo-compare comparison is organized:
| Protocol | Action |
|---|---|
| TCP | Compare whether the payloads are the same. If it is the same and the ack is the same then it is over. If it is the same but the ack of pvm is larger than the ack of svm, the packet sent to svm is dropped and the packet of pvm will not be sent (meaning sent back to the host NIC). So we will record the maximum ack in the current queue (both pvm and svm queues) until the ack exceeds the smaller of the two maximum ack values, and we can ensure that the packet payload is confirmed by both sides |
| UDP | only palyload checked |
| ICMP | only palyload checked |
| Other | only packet size checked |
Possible reasons for network packet loss are therefore:
- colo-compare did not receive the packet correctly
- svm’s redirector did not successfully forward packets to rewrite
- mirror did not replicate the packet successfully
- pvm’s redirector did not successfully send pvm’s return to colo-compare
- svm’s rewrite did not send/receive packets successfully
- colo-compare is not sending packets correctly
- svm’s redirector did not successfully forward packets to colo-compare
Problem processing
The processing of 1 mainly relies on the colo compare mechanism itself, for tcp packets will determine whether there are subsequent packets returned by ack, if there are subsequent packets, it means that the previous is missed
2 If the packet is not successfully sent to rewrite, it will not be processed by svm, so finally colo compare will encounter the situation where pvm has a packet but svm does not have a packet, and the processing is similar to 1
3 If mirror does not successfully copy the package, then there will also be a situation similar to 1, pvm exists package, svm no package
4 if pvm redirector did not successfully send the packet, then it seems from colo compare is pvm lost packets, but the same 1 processing, will wait for the pvm and svm minimum ack is exceeded, that is, both pvm or svm even if packet loss occurs, colo compare will wait for the updated packet to appear before returning the packet otherwise will always card does not reverse the current packet
5 If rewritte’s send-receive fails, this situation will cause the svm to not receive the packet and not return, similar to 1, but if failover occurs at this time, the svm packet is lost
6 this exception will lead to colo send and receive packet exceptions, network anomalies, not very well handled because itself colo compare is the core component
7 similar situation svm seems to have replied or actively sent the packet, but because colo compare did not receive, resulting in the svm within the data that did not reply, the benefit is that if the subsequent failover can occur, rewrite because the packet was recorded, will send the packet again, then it seems to be working again (need to test)
Trigger checkpoint
There are two conditions for triggering from colo-comare, because COLO-FT will establish a notification mechanism when it is established, and colo compare will trigger checkpoint from inside actively through this mechanism
- Checkpoint will be triggered if the payload of the compare tcp packet is inconsistent
- Timed to check if there is a certain period of time but has not received the same return packet (i.e., pvm, svm packet chain table content is inconsistent) trigger checkpoint
- If there is a packet in the pvm list but not in the secondary packet, then it means that the packet reply is late, this situation is handled by 2, if the comparison finds that the non-tcp packet comparison is inconsistent will trigger a checkpoint