What happened? Our CI/CD system ran integration test for every pull request but suddenly it met performance issue. Usually one round of integration test need 1h but this time almost all test do not finished after 1h 20min.
After check the codebase and test on lastest release stable branch, its more likely that the system met performance issue.
Before starting trip of “dig out the root cause”, check big picture of this CI/CD system architecture.
Prepare from perf Because integration test runs on virtual machine memory, check hypervisor’s performance might gave more details. So use perf to collect run time data for analysis.
1 2 3 4 5 git clone https://github.com/brendangregg/FlameGraph # or download it from github cd FlameGraph perf record -F 99 -a -g -- sleep 60 perf script | ./stackcollapse-perf.pl > out.perf-folded ./flamegraph.pl out.perf-folded > perf.svg
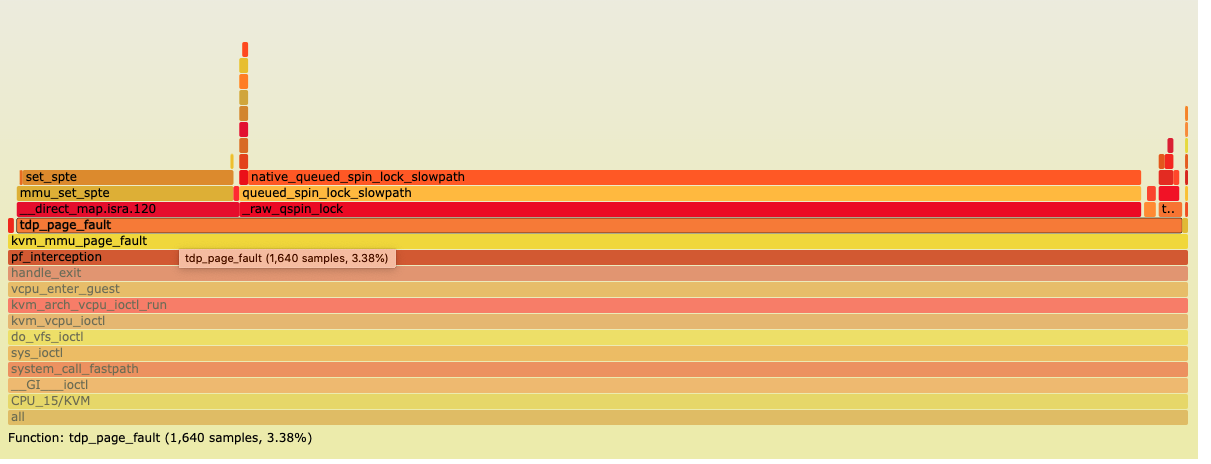
Check the flame graph
Start from tdp_page_fault Abviously cpu spend lots of time to handle tdp_page_fault
find definition from linux/arch/x86/kvm/mmu.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static void init_kvm_tdp_mmu(struct kvm_vcpu *vcpu) { struct kvm_mmu *context = &vcpu->arch.mmu; context->base_role.word = 0; context->base_role.guest_mode = is_guest_mode(vcpu); context->base_role.smm = is_smm(vcpu); context->base_role.ad_disabled = (shadow_accessed_mask == 0); context->page_fault = tdp_page_fault; context->sync_page = nonpaging_sync_page; context->invlpg = nonpaging_invlpg; context->update_pte = nonpaging_update_pte; context->shadow_root_level = kvm_x86_ops->get_tdp_level(vcpu); context->root_hpa = INVALID_PAGE; context->direct_map = true; context->set_cr3 = kvm_x86_ops->set_tdp_cr3; context->get_cr3 = get_cr3; context->get_pdptr = kvm_pdptr_read; context->inject_page_fault = kvm_inject_page_fault;
kvm_vcpu page_fault point to tdp_page_fault when mmu field of kvm_vcpu is initializing.
from kvm vcpu setup arch/x86/kvm/mmu.c
1 2 3 4 5 6 7 8 9 static void init_kvm_mmu(struct kvm_vcpu *vcpu) { if (mmu_is_nested(vcpu)) init_kvm_nested_mmu(vcpu); else if (tdp_enabled) init_kvm_tdp_mmu(vcpu); else init_kvm_softmmu(vcpu); }
from kvm vcpu setup arch/x86/kvm/mmu.c
1 2 3 4 5 6 void kvm_mmu_setup(struct kvm_vcpu *vcpu) { MMU_WARN_ON(VALID_PAGE(vcpu->arch.mmu.root_hpa)); init_kvm_mmu(vcpu); }
from kvm vcpu setup arch/x86/kvm/x86.c
1 2 3 4 5 6 7 8 9 int kvm_arch_vcpu_setup(struct kvm_vcpu *vcpu) { kvm_vcpu_mtrr_init(vcpu); vcpu_load(vcpu); kvm_vcpu_reset(vcpu, false); kvm_mmu_setup(vcpu); vcpu_put(vcpu); return 0; }
vcpu is created by
kvm_vm_ioctl_create_vcpu(struct kvm *kvm, u32 id)
check mmu in vcpu structure:
1 2 3 4 5 6 7 8 /* * Paging state of the vcpu * * If the vcpu runs in guest mode with two level paging this still saves * the paging mode of the l1 guest. This context is always used to * handle faults. */ struct kvm_mmu mmu;
Find more by pf_interception combine to flage graph, pf_interception is before tdp_page_fault,
1 2 3 4 5 6 7 8 9 10 static int pf_interception(struct vcpu_svm *svm) { u64 fault_address = __sme_clr(svm->vmcb->control.exit_info_2); u64 error_code = svm->vmcb->control.exit_info_1; return kvm_handle_page_fault(&svm->vcpu, error_code, fault_address, static_cpu_has(X86_FEATURE_DECODEASSISTS) ? svm->vmcb->control.insn_bytes : NULL, svm->vmcb->control.insn_len); }
refer to its usage:
1 [SVM_EXIT_EXCP_BASE + PF_VECTOR] = pf_interception
SVM_EXIT_EXCP_BASE is related to AMD CPU virtualization, PF_VECTOR means page_frame vector, used by page fault.
more details about the PF_VECTOR in arch/x86/kvm/svm.c
1 2 3 4 5 6 7 8 9 10 11 if (npt_enabled) { /* Setup VMCB for Nested Paging */ control->nested_ctl |= SVM_NESTED_CTL_NP_ENABLE; clr_intercept(svm, INTERCEPT_INVLPG); clr_exception_intercept(svm, PF_VECTOR); clr_cr_intercept(svm, INTERCEPT_CR3_READ); clr_cr_intercept(svm, INTERCEPT_CR3_WRITE); save->g_pat = svm->vcpu.arch.pat; save->cr3 = 0; save->cr4 = 0; }
if AMD CPU’s npt not enabled, PF_VECTOR will be used to intercept page fault.
So just quickly go through guest virtual address translation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /* * Fetch a guest pte for a guest virtual address */ static int FNAME(walk_addr_generic)(struct guest_walker *walker, struct kvm_vcpu *vcpu, struct kvm_mmu *mmu, gva_t addr, u32 access) ... ... ... error: errcode |= write_fault | user_fault; if (fetch_fault && (mmu->nx || kvm_read_cr4_bits(vcpu, X86_CR4_SMEP))) errcode |= PFERR_FETCH_MASK; walker->fault.vector = PF_VECTOR; walker->fault.error_code_valid = true; walker->fault.error_code = errcode;
error is defined to raise PF_VECTOR when failed to find any PTE(Page table entry)
Than let’s find the next method handle_exit() from svm.c
1 static int handle_exit(struct kvm_vcpu *vcpu)
following shows more details
1 2 3 struct vcpu_svm *svm = to_svm(vcpu); struct kvm_run *kvm_run = vcpu->run; u32 exit_code = svm->vmcb->control.exit_code;
the vcpu structure will be changed to vcpu_svm and than get the exit_code from it.
1 2 3 4 5 6 7 8 9 10 11 12 13 trace_kvm_exit(exit_code, vcpu, KVM_ISA_SVM); if (!is_cr_intercept(svm, INTERCEPT_CR0_WRITE)) vcpu->arch.cr0 = svm->vmcb->save.cr0; if (npt_enabled) vcpu->arch.cr3 = svm->vmcb->save.cr3; if (unlikely(svm->nested.exit_required)) { nested_svm_vmexit(svm); svm->nested.exit_required = false; return 1; }
than the exit_code will be traced.
CR0 has various control flags that modify the basic operation of the processor. See more: https://en.wikipedia.org/wiki/Control_register#CR0
if npt_enabled(CPU enable npt) vcpu will use vmcb saved cr3
vmcb: Intel VT-x name it as vmcs(virtual machine control structure), AMD name it as vmcb(virtual machine control block)
vmcb_control_area and vmcb_save_area combined as virtual machine control block.
note: need more research
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if (is_guest_mode(vcpu)) { int vmexit; trace_kvm_nested_vmexit(svm->vmcb->save.rip, exit_code, svm->vmcb->control.exit_info_1, svm->vmcb->control.exit_info_2, svm->vmcb->control.exit_int_info, svm->vmcb->control.exit_int_info_err, KVM_ISA_SVM); vmexit = nested_svm_exit_special(svm); if (vmexit == NESTED_EXIT_CONTINUE) vmexit = nested_svm_exit_handled(svm); if (vmexit == NESTED_EXIT_DONE) return 1; }
if vm is nested exit, handle nested exit next step, interrupts will be queued and if vm exit due to SVM_EXIT_ERR exit this thread.
1 2 3 4 5 6 7 8 9 10 svm_complete_interrupts(svm); if (svm->vmcb->control.exit_code == SVM_EXIT_ERR) { kvm_run->exit_reason = KVM_EXIT_FAIL_ENTRY; kvm_run->fail_entry.hardware_entry_failure_reason = svm->vmcb->control.exit_code; pr_err("KVM: FAILED VMRUN WITH VMCB:\n"); dump_vmcb(vcpu); return 0; }
last, check if the error code is external interrupt and not kernel handable error
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if (is_external_interrupt(svm->vmcb->control.exit_int_info) && exit_code != SVM_EXIT_EXCP_BASE + PF_VECTOR && exit_code != SVM_EXIT_NPF && exit_code != SVM_EXIT_TASK_SWITCH && exit_code != SVM_EXIT_INTR && exit_code != SVM_EXIT_NMI) printk(KERN_ERR "%s: unexpected exit_int_info 0x%x " "exit_code 0x%x\n", __func__, svm->vmcb->control.exit_int_info, exit_code); if (exit_code >= ARRAY_SIZE(svm_exit_handlers) || !svm_exit_handlers[exit_code]) { WARN_ONCE(1, "svm: unexpected exit reason 0x%x\n", exit_code); kvm_queue_exception(vcpu, UD_VECTOR); return 1; } return svm_exit_handlers[exit_code](svm);
finally invoke svm exit handler
1 return svm_exit_handlers[exit_code](svm);