这篇文章是基于上一篇 HOWTO 的一篇深入介绍以使用DPDK达成高性能用户态网络功能的vhost-user/virtio-pmd架构。本文主要是供对这个架构的更多实质性实现有兴趣的研发/架构师,并将会提供一个便于理解的时间博客来探索这些概念。
Introduction
之前的deep dive文章里,我们展示了将网络处理逻辑从qemu移动到kernel driver并通过vhost-net协议后带来的好处。这篇文章里,我们将会更深一步展示一下如何通过使用DPDK把host和guest的数据面从kernel移动到用户态之后获取更好的网络性能。为了实现这个我们需要看一下这个新的vhost-user库的实现。
在这篇文章的结尾,你应该对vhost-user/virtio-pmd架构有一个更深的理解,同时能够了解它系统重大性能提升背后的原因。
DPDK and its benefits
你可能已经听过DPDK了。这个用户态快速法宝处理库是很多网络功能虚拟化应用的核心(NFV,Network Function Virtualization),通过这个库他们可以实现一个完整的用户态应用,而跳过内核的网络协议栈.
DPDK是一组用户态的库,能够使一个用户创建一个优化过的高性能包处理应用。它带来了很多优势,让他在开发人员之中特别受欢迎。下面是列举一部分优势:
- Processor affinity DPDK可以把每一个不同的线程pin到一个特定的逻辑核心上来满足并行最大化
- Huge pages DPDK有数层内存管理(比如Mempool library或者是Mbuf libraty)。然而实际上所有的内存都mmap在hugetlbfs里面分配的。使用2MB或者是甚至1GB的页,DPDK减少了cache missi以及TLB的查询
- Lockless ring buffers DPDK包处理是基于Ring library的,它提供了一个高效无锁的ring queueu支持爆发式的入队出队操作。
- Poll Mode Driver 为了避免中断开销,DPDK提供了一个Poll Mode Driver(PMD)抽象
- VFIO支持 VFIO(Virtual Function I/O)提供了一个用户态驱动开发框架,允许用户态应用直接通过I/O空间映射到应用内存的方式直接访问硬件设备。
附带在这些特性之后的还有另外两个DPDK支持的技术,提供给我们一套极大提升网络应用性能的工具:
- Vhost-user库 用户态库,实现了vhost协议
- Virtio-PMD 基于DPDK的PMD抽象构建,virtio-pmd驱动实现了virtio标准,同时允许通过一个标准和有效的方式使用虚拟硬件。
DPDK and OVS: A perfect combination
一个关于DPDK提升性能的好例子就是Open VSwitch。这是一个功能丰富,多层的,分布式虚拟路由器,被广泛作为虚拟化环境以及SDN应用的主要网络层应用。
经典的OVS被划分为一个高效的基于内核的数据路径(fastpath)组合上一个flow table和一个比较慢的用户态数据路径(slowpath)处理不匹配任何flow(fastpath中已有的)的包。通过集成OVS和DPDK,fastpath也移动到了用户态,减少了kernel切换到用户态的交互,提升了最大性能。结果上对比原生的OVS,OVS+DPDK会有~10x的性能提升。
所以我们如何结合OVS-DPDK的这些特性和性能到一个virtio架构中去呢?接下来将一个一个介绍相关的组件。
Vhost-user library in DPDK
vhost协议是一组消息和机制,被设计用于将virtio数据处理路径从qemu卸载出来(the primary,主要是要卸载包处理)到一个外部元素(the handler,配置virtio rings以及实际的包处理)。最相关的机制是:
- 一组消息允许primary发送virtqueue内存的布局,并且配置到handler
- 一堆eventft类的文件描述符,允许guest不通过primary直接发送和接受handler的消息:Available Buffer Notification (从guest发送到handler同志有buffers可以被处理了)和 the Used Buffer Notification (从handler发送到guest说明buffers的处理解释了)
之前的virtio-networking文章我们描述了一个具体的vhost协议的实现(vhost-net内核模块)以及如何允许qemu把网络处理卸载到host-kernel上。然后我们介绍的vhost-user库,这个库是基于DPDK构建的,是一个vhost协议的用户态实现,允许qemu把virtio设备的包处理卸载到任意DPDK应用(比如Open vSwitch)。
vhost-user库和vhost-net kernel模块主要的不同是通信channel。vhost-net kernel驱动实现了是通过ioctls,而vhost-user库则是通过定义消息结构然后通过unix socket发送的。
DPDK应用可以被配置到提供unix socket(server模式)并且qemu可以连接上去(client模式)。然而,反过来也是可以的,这样就可以允许在不重启vm的情况下重启DPDK了。
在这个socket上,所有请求都被primary(这里是QEMU)初始化,其中一些请求要求返回的,比如GET_FEATURES请求或者其他设置了REPLY_ACK的请求。
在这个场景下,vhost-net kernel模块和vhost-user的库允许primary通过以下重要步骤配置数据面卸载
- Feature negotiation(特性协商):virtio特性和vhost-user-specific特性通过类似的方式协商,首先primary会获取handler的特性bitmask然后设置一个它支持的子集
- Memory region configuration(内存域配置):master设置内存域的分布,然后handler就可以mmap()这些内存了
- Vring configuration:primary会设置virtqueue的数量,并且设置他们在memory region内的地址。注意:vhost-user支持multiqueue所以设置更多的queue能用来改善性能。
- Kick and Call file descriptors sending:通常irqfd和ioeventfd机制生效。详细内容可以回顾【】。更多关于virtio queue的机制可以看virtio数据面的文章
总结一下这些机制,DPDK应用能够通过和guest共享内存处理包并且直接发送和接受guest的通知而不经过qemu。
最后一个把所有东西整合到一起的就是QEMU的virtio device模型,它有两个主要任务:
- 模拟virtio设备,在guest里面展示的i一个特定的PCI端口,并且可以被guest查询和完整配置。同时他会把ioeventfd映射到模拟设备的内存映射I/O空间,同时把irqfd映射到Global System Interrupt(GSI)。结果就是,guest对这些东西时没有感知的,通知和中断都会被转发到vhost-user库而没有qemu参与。
- 替换实际的virtio数据路径实现,这个设备作为vhost-user协议的master来卸载处理逻辑到vhost-user库的DPDK进程里
- 处理来自virtqueue的请求,并翻译成vhost-user的请求转发到slave。
下面的图展示了vhost-user-library作为DPDK应用的一部分的和QEMU交互以及guest使用virtio-device-model和virtio-pci设备:
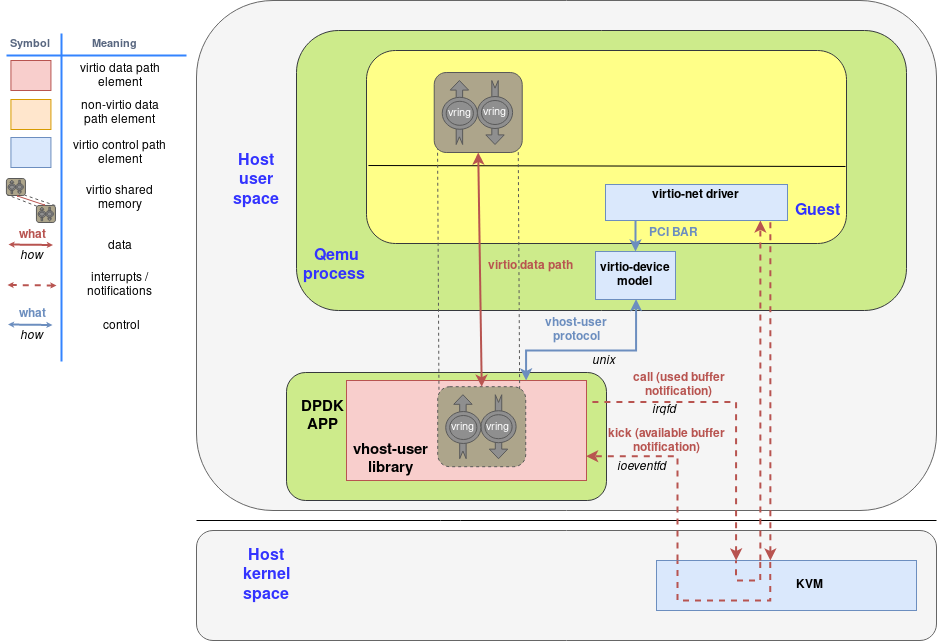
对这个图有一些需要提的点
- virtio memory region是guest初始化的
- 能正确相应的virtio驱动通过定义在virtio规范的标准配置PCI BARs和virtio device接口交互是正常的
- virtio-device-model(qemu内)使用vhost-user协议配置vhost-user库,同时配置irqfd和ioeventfd的文件描述符
- virtio memory region是guest分配并映射到vhost-user库的(可以是DPDK应用)
- 结果是DPDK应用能够直接读写包到guest内存,并通过ioeventfd和irqfd机制直接通知guest
Userland Networking in the guest
我们已经介绍了DPDK vhost-user实现,允许我们从host内核(vhost-net)卸载数据路径处理逻辑到专门的DPDK用户态应用(比如open vSwitch)因此动态改进了网络的性能。现在,我们将继续了解如何对guest做一样的改动来运行一个高性能网络应用(比如NFV服务)到guest的用户态来替换virtio-net内核模块。
为了能够直接在设备上运行用户态网络应用,我们需要三个组件:
- VFIO:VFIO是一个用户态驱动开发框架,允许用户态应用直接和设备交互(跳过kernel)
- Virtio-pmd驱动:是一个DPDK驱动,基于Poll Mode Driver抽象构建,实现了virtio协议
- IOMMU驱动:IOMMU驱动管理了虚拟IOMMU(I/O Memory Management Unit),一个可以对DMA-capable设备执行地址映射的模拟设备
接下来我们一个一个的描述他们的细节吧。
VFIO
VFIO是Virtual Function I/O的缩写。然而,Alex Williamson,vfio-pci kernel驱动的maintainer建议叫它 “Versatile Framework for userspace I/O”,这是一个更加准确的名字。VFIO是一个构建用户态驱动的基础框架,它提供了:
- 映射设备配置和I/O memory regions到用户内存
- DMA和驱动的重新映射以及基于IOMMU groups的隔离。后面我们会深入介绍IOMMU以及它是如何工作的,目前假设它允许创建映射到物理内存的虚拟I/O内存空间(类似普通MMU映射到non-IO虚拟内存),所以当一个设备想要DMA到虚拟I/O地址,IOMMU将重新映射该地址并可能应用隔离和其他安全策略
- Eventfd和irqfd 基础信号机制支持用户态的信号和中断
引用内核文档:“如果你想在VFIO之前写一个驱动,你要么必须经历完整的开发周期才能成为合适的上游驱动,要么在代码树之外维护,要么使用没有IOMMU保护概念的UIO框架,限制中断支持并需要root权限才能访问诸如PCI配置空间之类的东西。”
VFIO暴露了用户友好的API,用于创建character设备(在 /dev/vfio/)支持ioctl通过device descriptor来描述设备、I/O regions 和 他们的读/写/mmap offsets,同时提供机制来描述和注册中断通知。
Virtio-pmd
DPDK提供了一个叫做Poll Mode Driver (PMD)的驱动抽象。这个东西作用在设备驱动和用户应用之间。提供了一系列高灵活性的东西给用户应用,同时保证了拓展性。比如给新设备实现驱动的能力。
它提供的一些更有用的特性如下:
- 一组API允许特定的驱动实现驱动标准包括接收和发送方法。
- 每个端口和每个队列硬件的卸载支持静态和动态配置
- 一个用于数据的可拓展API可用,允许驱动定义自己的驱动标准的数据,同时应用可以调查回溯这些数据
virtio Poll Mode Driver(virtio-pmd)是众多使用PMD API的一个驱动之一,为使用DPDK编写的应用程序提供对virtio设备的快速无锁访问,使用virtio的virtqueues提供数据包接收和传输的基本功能。
除了这些PMD的特性之外,virtio-pmd驱动的实现还支持:
- 接收时每个数据包可灵活合并缓冲区和发送时每个数据包的分散缓冲区
- 组播和混杂模式
- MAC/vlan过滤
结果就是一个高性能的用户态virtio驱动允许DPDK应用完整的使用virtio标准接口。
Introducing the IOMMU
IOMMU可以说基本上等于I/O空间(设备通过DMA直接访问内存)的MMU。它位于主存和设备之间,创建一个virtual I/O空间给每个设备,提供一个机制,动态映射虚拟内存到无力设备。因此当一个驱动配置了设备的DMA(比如一个网卡),并且配置了虚拟地址,当设备尝试访问虚拟地址的时候,这些虚拟地址就被IOMMU重新映射了。
它提供了很多优势比如:
- 可以分配大段相邻虚拟内存,而不需要相邻物理内存
- 一些设备不支持足够长的访问物理内存的地址,IOMMU解决了这个问题
- 保护内存,避免DMA攻击通过恶意构造错误的设备并执行访问了并不是分配给设备的内存空间。设备只能看到虚拟地址并且运行操作系统独占的IOMMU映射。
- 一些架构里支持中断重映射,允许中断隔离和迁移
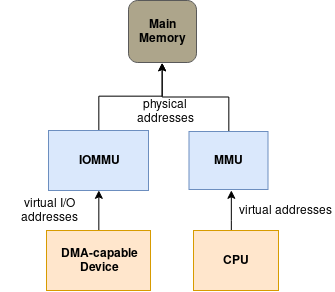
通常情况下,所有东西都是有代价的,IOMMU的缺点是:
- 因为要做page translation,所以性能下降
- 如果增加page translation表会消耗物理内存
vIOMMU - IOMMU for the guest
当然,如果有一个物理IOMMU(比如intel VT-d和AMD-VI)qemu里也是会存在虚拟IOMMU的。QEMU的vIOMMU有以下特征:
- 它翻译guest I/O虚拟地址(IOVA)到guest物理地址(GPA),并且能够通过QEMU的内存管理系统翻译成QEMU的host虚拟地址(HVA)
- 设备隔离执行
- 实现了I/O TLB API,因此映射可以在qemu外部查询
因此为了获取一个虚拟设备和虚拟IOMMU协作:
- 使用一个可用API在vIOMMU创建一个必要的IOVA映射,目前API是:
a. 内核驱动的内核DMA API
b. 用户态驱动的VFIO - 用虚拟I/O地址配置设备的DMA
vIOMMU and DPDK integration
当一个QEMU模拟的设备尝试DMA到guest的virtio I/O空间,会使用到vIOMMU TLB来查询对应的页的映射并且执行一个安全的DMA访问。问题是如果实际的DMA被卸载到外部进程比如一个使用vhost-user库的DPDK应用?
当vhost-user库尝试直接访问这些共享内存,它需要把所有地址(I/O虚拟地址)到它自己的地址。因此这个需要让QEMU的vIOMMU来提供Device TLB API。Vhost-user库(或者说是vhost-kernel驱动)使用PCIe’s Address Translation Services标准消息集合来向QEMU请求一个页地址的翻译,通过一个次级的通信channel(另一个unix socket)这个channel会在配置IOMMU的时候创建。
总的来说,这里一共有三次地址翻译需要被处理:
- Qemu的vIOMMU翻译I/O虚拟地址到Guest物理地址
- Qemu的内存管理翻译Guest物理地址到Host虚拟地址(在qemu进程的地址空间内的Host虚拟地址)
- Vhost-user库翻译Qemu的Host虚拟地址到Vhost-user的Host虚拟地址。通常情况下,当vhost-user库映射qemu内存地址的时候,很简单就是把QEMU的Host虚拟地址翻译到mmap返回的地址即可
显然,这些地址翻译存在潜在的性能影响,特别是使用的是动态映射。然而,静态的大页分配(也是DPDK实际上做的)可以最小化这些性能损失。
下面的图优化了之前的vhost-user架构,来包含IOMMU的组件:
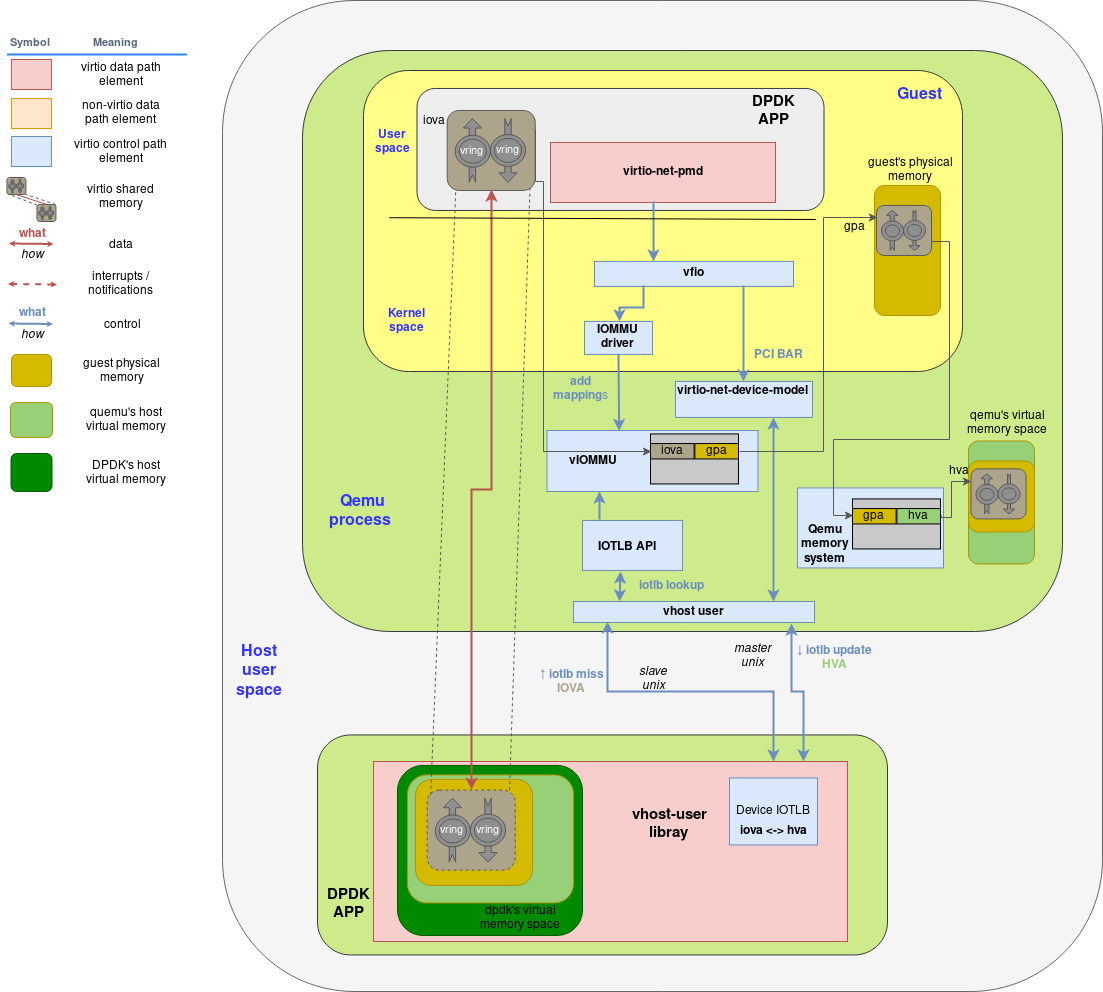
关于这个相当复杂的图表要提几点:
- Guest物理内存空间是从Guest视角当作物理内存空间的,但显然这是QEMU进程的虚拟地址。当virtqueue memory region被分配的时候,实际上是在Guest的物理内存空间里
- 当I/O虚拟地址分配给包含virtqueue的内存范围,和Guest物理地址相关联的一个条目就会被增加到vIOMMU的TLB table里
- 另一方面,qemu的内存管理系统是能够知道guest的物理内存空间的和它自己的内存空间是在一起的。因此qemu的内存管理系统是可以翻译guest物理地址到QEMU(host)虚拟地址的
- 当vhost-user库尝试去访问未被翻译过的IOVA的时候,它会通过secondary unix socket发送一个IOTLB miss的消息
- IOTLB API收到这个请求后就会开始查找这个地址,首先是把IOVA翻译成GPA然后GPA翻译成HVA。然后发送这个翻译好的结果到master的unix socket也就是vhost-user库。
- 最后,vhost-user库需要做最后一次翻译,因为qemu的内存被映射到了自己的内存空间里,所以需要把QEMU的HVA翻译到自己的HVA来访问共享内存
Putting everything together
这个文章涵盖了大量的组件,包括DPDK,virtio-pmd,VFIO,IOMMU等等
下面的图展示了把这些组件整合之后实现的vhost-user/virtio-pmd架构:
对这个图标要提一点:
- 把这个图和上一个图相比,增加了通过硬件IOMMU,VFIO以及特定vendor的PMD驱动,连接OVS-DPDK应用到物理网卡的组件。现在就不会有疑惑了,因为访问硬件的方式和guest是一样的。
An example flow
Control Plane
这是设置控制面必要的步骤
- 当host上的DPDK应用(OVS)启动,会创建一个socket(server模式)和qemu处理virtio相关的协商逻辑
- 当qemu启动,它会连接到main socket,然后如果检测到VHOST_USER_PROTOCOL_F_SLAVE_REQ如果vhost-user提供了这个特性,qemu就会创建一个second socket并且把这个socket发送到vhost-user来连接并发送IOTLB同步消息
- 当QEMU <-> vhost-library的协商结束,两个sockets在他们之间是共享的。一个是virtio配置,另外一个是iotlb消息交换用的
- guest启动然后vfio驱动就和PCI设备绑定了。这个驱动能够提供访问iommu groups(iommu group主要取决于硬件拓扑)
- 当DPDK在guest里启动的时候有以下步骤
a. 初始化PCI-vfio设备,同时映射PCI配置空间到用户内存
b. 分配virtqueue
c. 使用vfio,DMA映射virtqueue内存空间,这样通过IOMMU内核驱动dma映射到vIOMMU设备
d. 然后,virto特性协商就开始了。本场景里,使用的virtqueue的地址是IOVA(在I/O虚拟内存空间)。映射eventfd和irqfd也完成了,因此中断和通知就被直接路由在guest和vhost-user库之间,而没有QEMU参与
e. 最后,DPDK应用分配一个大片的连续内存作为网络buffer。这部分映射也通过VFIO和IOMMU驱动添加到vIOMMU
到此,配置完成并且数据面(virtqueues和notification机制)已经可以使用了。
Data Plane
为了发送数据包,会有以下步骤:
- guest里的DPDK应用命令virtio-pmd发包。首先会写buffers然后把一致性描述符增加到可用描述符ring里
- vhost-user PMD在host端会polling这个virtioqueue,所以他立刻会检测到新的描述符可用并开始处理
- 对每一个描述符,vhost-user PMD都会map他们的buffer(这一步就是地址翻译,翻译IOVA到HVA)。很少情况下会有buffer内存在一个没被映射到vhost-user IOTLB的页,如果出现miss的情况,会发送一个请求给QEMU,而实际上DPDK应用在guest里会分配静态大页,保证IOTLB请求会被最小限度的发送到QEMU。
- 这个vhost-user PMD会把这个buffers拷贝到mbufs(也就是DPDK应用使用的message buffers)
- 这些描述符会被添加到使用过的描述符ring。这些会立刻被guest里的DPDK应用发现,因为guest里的DPDK应用会不断polling virtqueue
- 然后这些mbufs就被host的DPDK应用消费了
Summary and conclusions
DPDK是一个很有前途的技术,因为他提供工了极大提升用户态性能的能力。不仅这个技术本身,和OVS结合,能够满足灵活高效的现代虚拟环境的要求,也在NFV部署中扮演着一个重要的角色。
为了充分利用这个技术,数据中心交换数据路径以及在guest中启用NFV应用,有必要在host和guest之间安全的创建一个有效的数据路径。这也就是virtio-net技术起到的作用。
vhost-user提供了一个可靠并且安全的机制来卸载网络处理逻辑到基于DPDK的应用里。它和vIOMMU集成,并提供隔离和内存保护,同时将libvirt从处理数据包的繁重工作下解放出来。
在guest里,符合virtio标准DPDK(virtio-pmd)利用有效的内存管理和高性能的DPDK Poll Mode driver使得在guest里创建也能创建快速数据路径。
如果你想要学习更多关于virtio技术,vhost-user以及DPDK请不要错过下一篇文章。