but linux guest kernel let intel cpu use tsc and as the result intel vs amd cpu has below differences.
go through kernel code
Code snippet 0
1 2 3 4 5
/* * TSC can be unstable due to cpufreq or due to unsynced TSCs */
staticint __read_mostly tsc_unstable;`
The code defines a static integer variable tsc_unstable. The static keyword means that this variable is only visible within the file it’s defined in, limiting its scope to tsc.c. This is a common practice when you want to keep the variable private to a particular file and prevent it from being accessed directly from other files.
The __read_mostly attribute is a compiler directive specific to the Linux kernel, which suggests that this variable is expected to be read from often, but seldom written to. This can help the compiler optimize the generated code for this access pattern.
The variable tsc_unstable is used to indicate whether the TSC is unstable. The comment above the variable declaration explains that the TSC can be unstable due to CPU frequency scaling (cpufreq) or due to unsynchronized TSCs across different cores or processors.
In terms of improvements, the code is quite clear and concise. However, it might be helpful to expand the comment to explain what the implications of an unstable TSC are, and how the tsc_unstable variable is used in the system’s logic.
Code snippet 1
1 2 3 4 5 6 7 8 9 10 11 12
static int __init tsc_setup(char *str) { if (!strcmp(str, "reliable")) tsc_clocksource_reliable = 1; if (!strncmp(str, "noirqtime", 9)) no_sched_irq_time = 1; if (!strcmp(str, "unstable")) mark_tsc_unstable("boot parameter"); if (!strcmp(str, "nowatchdog")) no_tsc_watchdog = 1; return 1; }
The __init keyword before the function name is a macro used in the Linux kernel to indicate that this function is used only at initialization time. The memory for this function is freed after the initialization is complete to conserve the kernel’s memory footprint.
Inside the function, there are several if statements that compare the input string str to different string literals using the strcmp and strncmp functions. strcmp compares two strings and returns 0 if they are identical, while strncmp compares up to a specified number of characters from two strings.
If str is “reliable”, it sets the tsc_clocksource_reliable variable to 1. If str starts with “noirqtime”, it sets the no_sched_irq_time variable to 1. If str is “unstable”, it calls the mark_tsc_unstable function with “boot parameter” as an argument. If str is “nowatchdog”, it sets the no_tsc_watchdog variable to 1.
Each of these variables or functions presumably controls a different aspect of the TSC’s behavior. For example, tsc_clocksource_reliable might indicate whether the TSC is a reliable source of time, and no_sched_irq_time might control whether the scheduler uses the TSC for interrupt timing.
In terms of improvements, the function is quite clear and concise. However, adding comments to explain the purpose of each variable and what each string argument represents would improve readability. It would also be beneficial to add error handling to account for the case where str does not match any of the expected values.
And we could use tsc=reliable to kernel cmdline to changes to tsc clock source.
Code snippet 2
1 2 3 4 5 6 7 8 9 10 11
static void tsc_cs_mark_unstable(struct clocksource *cs) { if (tsc_unstable) return; tsc_unstable = 1; if (using_native_sched_clock()) clear_sched_clock_stable(); disable_sched_clock_irqtime(); pr_info("Marking TSC unstable due to clocksource watchdog\n"); }
The function first checks if the tsc_unstable variable is already set to 1. If it is, the function immediately returns, as the TSC has already been marked as unstable. This is a common pattern in C programming known as a “guard clause”, which is used to exit a function early when certain conditions are met.
If tsc_unstable is not set to 1, the function proceeds to mark the TSC as unstable. It does this by setting tsc_unstable to 1, and then calling two functions: clear_sched_clock_stable and disable_sched_clock_irqtime. These functions presumably perform some cleanup or configuration changes related to the TSC becoming unstable.
Finally, the function logs a message using the pr_info macro, which is a kernel print function that outputs a message to the system log. The message indicates that the TSC has been marked as unstable due to the clocksource watchdog.
In terms of improvements, the function is quite clear and concise. However, adding comments to explain the purpose of the clear_sched_clock_stable and disable_sched_clock_irqtime functions would improve readability. It would also be beneficial to add error handling to account for any potential issues that could occur when these functions are called.
/* * Make an educated guess if the TSC is trustworthy and synchronized * over all CPUs. */ int unsynchronized_tsc(void) { if (!boot_cpu_has(X86_FEATURE_TSC) || tsc_unstable) return 1; #ifdef CONFIG_SMP if (apic_is_clustered_box()) return 1; #endif if (boot_cpu_has(X86_FEATURE_CONSTANT_TSC)) return 0; if (tsc_clocksource_reliable) return 0; /* * Intel systems are normally all synchronized. * Exceptions must mark TSC as unstable: */ if (boot_cpu_data.x86_vendor != X86_VENDOR_INTEL) { /* assume multi socket systems are not synchronized: */ if (num_possible_cpus() > 1) return 1; } return 0; }
The function begins by checking if the boot CPU has the TSC feature and if the TSC is unstable. If either of these conditions is true, the function immediately returns 1, indicating that the TSC is unsynchronized.
Next, if the system is configured for symmetric multiprocessing (SMP), the function checks if the Advanced Programmable Interrupt Controller (APIC) is clustered. If it is, the function returns 1, again indicating that the TSC is unsynchronized.
The function then checks if the boot CPU has the constant TSC feature or if the TSC clocksource is reliable. If either of these conditions is true, the function returns 0, indicating that the TSC is synchronized.
Finally, the function checks if the CPU vendor is not Intel. If it is not, and the system has more than one possible CPU, the function returns 1, indicating that the TSC is unsynchronized. If none of the previous conditions are met, the function returns 0, indicating that the TSC is synchronized.
More practice
SystemTap
Because of above issue, I just spent more time to check the tsc value used by guest and from host cpu do have any different. With systemtap.
observe rdtsc
result
value of tsc clock,average value and stantard deviation has different
and the value from guest os is not stable when compared with host
during live migration, tsc value will be smaller than usual (I think its because live migration has down time, so we need to change tsc to tolerant it)
so just from the small test, its not a good idea to relay on tsc which is not as specific as it on the host
data from my test
The first version, use the script test average value and stantard deviation
in guest:
1 2 3 4 5 6
TSC mean: 2000170717.800000, TSC std dev: 255861.233545 Time mean: 1000101683.030000, Time std dev: 162898.956256 TSC mean: 2000158595.200000, TSC std dev: 340159.343486 Time mean: 1000092746.020000, Time std dev: 170311.019513 TSC mean: 2000116749.600000, TSC std dev: 96417.905701 Time mean: 1000076448.860000, Time std dev: 102460.953979
in guest during live migration:
1 2 3 4
TSC mean: 1990107194.600000, TSC std dev: 71113321.983521 Time mean: 1000129868.770000, Time std dev: 340417.298586 TSC mean: 1993829457.200000, TSC std dev: 47439246.502752 Time mean: 1001882162.230000, Time std dev: 16929541.16989
Samples from host:
1 2 3 4 5 6
TSC mean: 2000087563.600000, TSC std dev: 16626.290598 Time mean: 1000065114.610000, Time std dev: 8341.142215 TSC mean: 2000084499.400000, TSC std dev: 4760.334824 Time mean: 1000063541.340000, Time std dev: 2447.439965 TSC mean: 2000083391.800000, TSC std dev: 11786.744451 Time mean: 1000062911.800000, Time std dev: 5922.538748
TSC average value will be less that normal during migration.
change the script to check abnormal samples
1 2 3 4 5 6 7
Sample 54, TSC diff: 1998893560, Time diff: 1000069363 ns Sample 55, TSC diff: 1998887140, Time diff: 1000065570 ns Sample 56, TSC diff: 1999007020, Time diff: 1000130480 ns Sample 57, TSC diff: 1535293100, Time diff: 1000090774 ns Sample 58, TSC diff: 1998899520, Time diff: 1000073836 ns Sample 59, TSC diff: 2000588260, Time diff: 1001300447 ns Sample 60, TSC diff: 1998899540, Time diff: 1000072444 ns
Time Stamp Counter (TSC)All 80x86 microprocessors include a CLK input pin, which receives the clock signal of an external oscillator. Starting with the Pentium, 80x86 microprocessors sport a counter that is increased at each clock signal, and is accessible through the TSC register which can be read by means of the rdtsc assembly instruction. When using this register the kernel has to take into consideration the frequency of the clock signal: if, for instance, the clock ticks at 1 GHz, the TSC is increased once every nanosecond. Linux may take advantage of this register to get much more accurate time measurements.
Phenomenon: When creating a new virtual machine, after the virtual machine enters the “running” state (libvirt reports running, and the qemu process starts), a disk is loaded. During the kernel startup process, the disk (vdb) is recognized, and then qemu receives a device removal event, which is fed back to libvirt. Libvirt updates the XML, causing inconsistency between the disk state recorded in the zstack database and the XML on the host.
The main issue here is that the libvirt loading device interface returns success, and the XML corresponding to the device is also added. However, this device is deleted according to the event feedback from qemu.
Important log information: Here, let’s first analyze the system logs in the guest OS:
Here, we notice the logs related to pciehp because this virtual machine is UEFI-booted, leading to numerous pcie-related logs (due to UEFI boot requiring the q35 machine type, which defaults to pcie devices).
The initially observed logs include an error log from pcieport:
1
pci 0000:00:02.7: BAR 13: failed to assign [io size 0x1000]
Subsequently, through ausearch, it is identified that libvirt received a device deletion event, leading to the removal of the mentioned device:
libvirt received device deleted event, removing the device
Based on these scenarios, we have summarized the steps to reproduce the issue:
During the kernel startup process
Load the data disk.
Check for inconsistencies between the XML and the database.
Through repeated testing of VM boot and data disk loading, the issue can be reproduced.
Regarding the error logs mentioned above, the explanation is as follows:
pci 0000:00:02.7: BAR 13: failed to assign [io size 0x1000]:
According to https://access.redhat.com/solutions/3144711, this error may occur because in virtualized environments, there might be more PCIe ports than in a real physical environment, leading to this error. However, it does not have any actual impact.
“Attention button pressed” indicates that when resetting the PCIe slot, QEMU sends the corresponding interrupt. When the host receives this interrupt, the corresponding processing logic prints this log.
As for the key QEMU code, by searching the codebase, it has been confirmed that QEMU sends the corresponding interrupt when resetting the PCIe slot, and the host prints the log as part of the corresponding processing logic.
code from pcie.c
1 2 3 4 5 6
pci_word_test_and_clear_mask(exp_cap + PCI_EXP_SLTSTA, PCI_EXP_SLTSTA_EIS |/* on reset, the lock is released */ PCI_EXP_SLTSTA_CC | PCI_EXP_SLTSTA_PDC | PCI_EXP_SLTSTA_ABP);
which is used in qdev.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
QLIST_FOREACH(bus, &dev->child_bus, sibling) { object_property_set_bool(OBJECT(bus), true, "realized", &local_err); if (local_err != NULL) { goto child_realize_fail; } } if (dev->hotplugged) { device_reset(dev); } dev->pending_deleted_event = false; if (hotplug_ctrl) { hotplug_handler_plug(hotplug_ctrl, dev, &local_err); if (local_err != NULL) { goto child_realize_fail; } }
During the device hotplug process, there will be a reset action.
static int pciehp_poll(void *data) { struct controller *ctrl = data; schedule_timeout_idle(10 * HZ); /* start with 10 sec delay */ while (!kthread_should_stop()) { /* poll for interrupt events or user requests */ while (pciehp_isr(IRQ_NOTCONNECTED, ctrl) == IRQ_WAKE_THREAD || atomic_read(&ctrl->pending_events)) pciehp_ist(IRQ_NOTCONNECTED, ctrl); if (pciehp_poll_time <= 0 || pciehp_poll_time > 60) pciehp_poll_time = 2; /* clamp to sane value */ schedule_timeout_idle(pciehp_poll_time * HZ); } return 0; } /* Check Attention Button Pressed */ if (events & PCI_EXP_SLTSTA_ABP) { ctrl_info(ctrl, "Slot(%s): Attention button pressed\n", slot_name(ctrl)); pciehp_handle_button_press(ctrl); }
This code represents a kernel function for polling PCIe Hot Plug events. It uses a kernel thread (kthread) to continuously poll for interrupt events or user requests related to PCIe Hot Plug. The function includes a timeout mechanism with an initial delay of 10 seconds and then repeats the polling process based on the specified polling time. The function stops when the kernel thread should stop (kthread_should_stop() returns true).
And pciehp_handle_button_press is implemented as following:
void pciehp_handle_button_press(struct controller *ctrl) { mutex_lock(&ctrl->state_lock); switch (ctrl->state) { case OFF_STATE: case ON_STATE: if (ctrl->state == ON_STATE) { ctrl->state = BLINKINGOFF_STATE; ctrl_info(ctrl, "Slot(%s): Powering off due to button press\n", slot_name(ctrl)); } else { ctrl->state = BLINKINGON_STATE; ctrl_info(ctrl, "Slot(%s) Powering on due to button press\n", slot_name(ctrl)); } /* blink power indicator and turn off attention */ pciehp_set_indicators(ctrl, PCI_EXP_SLTCTL_PWR_IND_BLINK, PCI_EXP_SLTCTL_ATTN_IND_OFF); schedule_delayed_work(&ctrl->button_work, 5 * HZ); break; case BLINKINGOFF_STATE: case BLINKINGON_STATE: /* * Cancel if we are still blinking; this means that we * press the attention again before the 5 sec. limit * expires to cancel hot-add or hot-remove */ ctrl_info(ctrl, "Slot(%s): Button cancel\n", slot_name(ctrl)); cancel_delayed_work(&ctrl->button_work); if (ctrl->state == BLINKINGOFF_STATE) { ctrl->state = ON_STATE; pciehp_set_indicators(ctrl, PCI_EXP_SLTCTL_PWR_IND_ON, PCI_EXP_SLTCTL_ATTN_IND_OFF); } else { ctrl->state = OFF_STATE; pciehp_set_indicators(ctrl, PCI_EXP_SLTCTL_PWR_IND_OFF, PCI_EXP_SLTCTL_ATTN_IND_OFF); } ctrl_info(ctrl, "Slot(%s): Action canceled due to button press\n", slot_name(ctrl)); break; default: ctrl_err(ctrl, "Slot(%s): Ignoring invalid state %#x\n", slot_name(ctrl), ctrl->state); break; } mutex_unlock(&ctrl->state_lock); }
Both OFF_STATE and ON_STATE could changed to each other by same press request.
Based on the test results, we preliminarily conclude that there is a race condition between hot-plug operations and kernel boot, leading to unexpected changes in the PCIe slot’s state from off → on → off. (Note: The crucial point here is that pciehp_handle_button_press(ctrl); simultaneously handles both on and off scenarios.)
With reference to the above keywords, we identified a related Bugzilla entry for QEMU version 4.2 by searching for ‘qemu pci device kernel boot race condition’:
“The document mentions a virtio-net failover mechanism introduced by QEMU 4.2, addressing the issue of hot-plugging network cards failing during the VM startup phase. This problem arises from a race condition in the QEMU code that sets the PCIe slot’s state. The provided QEMU patch resolves the issue:
The title of this patch is: ‘pcie: don’t set link state active if the slot is empty.’
Upon reviewing its content, it appears that during PCIe initialization and the hot-plug phase, the ‘reset’ is called, potentially causing inconsistencies in the slot’s state. This patch addresses the problem by preventing the setting of the link state to active if the slot is empty, eliminating the observed issue.”
TIPs:
Search for changes related to the virtual machine process using ausearch:
1
ausearch -m "VIRT_RESOURCE" -p 63259
Libvirt’s XML and QEMU event update mechanism: Details can be found in TIC-1360 - Cloud VM disk does not exist, capacity inconsistency between UI interface and underlying view (Closed).
The physical layout of CPU cores in a system is known as CPU topology. Understanding CPU topology can significantly impact the performance of a system, as it determines the effectiveness and efficiency of the cores.
What is CPU Topology?
CPU topology comprises three primary levels:
Socket: A physical connector that holds a CPU. A system can have multiple sockets, each of which can hold multiple cores.
Core: A single processing unit within a CPU that can run multiple threads simultaneously.
Thread: A single flow of execution within a core.
The CPU topology can be described using a tree-like structure, with the socket level at the top and the thread level at the bottom. The cores in a socket are connected to each other via a bus, and the threads in a core are connected to each other by a shared cache.
Importance of CPU Topology
Understanding CPU topology is crucial for improving system performance. The topology can be used to optimize the performance of a system by assigning threads to cores in a way that minimizes the amount of communication between cores. This can enhance the performance of applications that are heavily multithreaded.
Additionally, the CPU topology can be used to troubleshoot performance issues. For example, if an application is running slowly, the CPU topology can be used to identify which cores are being used the most. This information can help identify the source of the performance problem and take appropriate steps to improve it.
Here are some benefits of understanding CPU topology:
It helps to optimize system performance by assigning tasks to the most suitable cores.
It helps to troubleshoot performance issues by identifying heavily used cores.
It helps to understand how the system will scale as more cores are added.
Tools to Display CPU Topology
There are several tools available to display CPU topology, and one of the most commonly used tools is lscpu. Here is an example of using lscpu to display CPU topology:
Virtual machines (VMs) are software programs that create an isolated environment for running operating systems and applications. VMs are often used to run various operating systems on the same physical machine or to run applications that require more resources than are available on the host machine.
When a VM is created, the hypervisor, which manages the VMs, assigns a single thread to the VM. This is because assigning multiple threads to a VM can lead to performance issues. Threads share the same resources on a core, and multiple threads can compete for resources, leading to contention and slowdowns. Furthermore, threads may interfere with each other, causing further slowdowns.
To optimize VM performance, it’s generally best to assign a single thread to a VM. However, there are exceptions to this rule. For example, if a VM is running an application that is specifically designed to take advantage of multiple threads, it may be beneficial to assign multiple threads to the VM.
To take advantage of multiple threads in a virtual machine, it’s essential to use a hypervisor that supports thread pinning, an operating system that supports thread scheduling, and an application that is designed to take advantage of multiple threads. Multithreaded applications such as web servers, database servers, and media transcoders are good examples of applications that can take advantage of multiple threads.
Why thread of cpu toplogy always 1 or 2
There are two main reasons why the number of threads in a CPU topology is usually limited to 1 or 2:
Physical constraints: A CPU core can only run a single thread at a time due to having a single instruction pointer (IP) and a single set of registers. When two threads run on the same core, they compete for the same resources, leading to performance degradation.
Scheduling overhead: Scheduling threads on different cores can be expensive, as the operating system has to switch between threads and this may cause context switches. Context switches are costly, as they require the operating system to save the state of the current thread and restore the state of the next.
In some cases, having more than two threads per core may be beneficial. For instance, heavily multithreaded applications may take advantage of the extra threads. However, in most cases, the costs of having more than two threads per core outweigh the benefits.
There are a few exceptions to the rule that the number of threads in a CPU topology is usually limited to 1 or 2. For example, some CPUs support hyper-threading, which allows a single core to run two threads simultaneously. However, hyper-threading is not always a good idea, as it can sometimes lead to performance degradation.
Overall, the number of threads in a CPU topology is usually limited to 1 or 2 due to physical constraints and scheduling overhead. While there are exceptions, in most cases, the costs of having more than two threads per core outweigh the benefits.
Sockets and cores with performance
Sockets and cores do have an impact on performance.
Sockets: A socket is a physical connector that holds a CPU. A system can have multiple sockets, each of which can hold multiple cores. The more sockets a system has, the more cores it can have, which can lead to better performance.
Cores: A core is a single processing unit within a CPU. A core can run multiple threads simultaneously. The more cores a system has, the more threads it can run, which can also lead to better performance.
However, it’s important to note that the number of sockets and cores is not the only factor that affects performance. Other factors, such as the clock speed of the CPU, the amount of cache memory, and the type of memory, can also have a significant impact.
In general, systems with more sockets and cores will have better performance than systems with fewer sockets and cores. However, it’s important to choose a system that has the right balance of sockets, cores, clock speed, cache memory, and memory type for your needs.
Here are some examples of how sockets and cores can impact performance:
A system with two sockets and four cores will have better performance than a system with one socket and two cores. This is because the system with two sockets can run more threads simultaneously.
A system with a higher clock speed will have better performance than a system with a lower clock speed. This is because the system with a higher clock speed can execute instructions faster.
A system with more cache memory will have better performance than a system with less cache memory. This is because the system with more cache memory can store more data in memory, which reduces the number of times the CPU has to access slower memory.
A system with faster memory will have better performance than a system with slower memory. This is because the system with faster memory can transfer data to the CPU faster, which reduces the amount of time the CPU has to wait for data.
Why aws only offer single sockets instance?
There are a few reasons why cloud providers like AWS do not offer multi-socket instances.
Cost: Multi-socket instances are more expensive than single-socket instances. This is because they require more hardware, such as more CPUs and more memory.
Complexity: Multi-socket instances are more complex to manage than single-socket instances. This is because they have more components, such as more CPUs, more memory, and more storage.
Performance: Multi-socket instances do not always offer better performance than single-socket instances. This is because the performance of a multi-socket instance can be limited by the speed of the interconnect between the sockets.
For these reasons, cloud providers like AWS choose to offer single-socket instances. Single-socket instances are less expensive, easier to manage, and offer the same or better performance than multi-socket instances.
However, there are some cases where multi-socket instances may be a good choice. For example, if you need a lot of CPU power, or if you need to run applications that are not well-optimized for multi-threading, then a multi-socket instance may be a good option.
If you are considering using a multi-socket instance, it is important to weigh the costs and benefits carefully. You should also make sure that your applications are well-optimized for multi-threading.
Virtio memory ballooning is a technique that adjusts memory allocation in virtualized environments. The hypervisor can add or remove memory from a virtual machine based on demand, using a balloon driver in the guest operating system. When demand is high, the balloon driver inflates and the guest operating system releases memory. When demand is low, the balloon driver deflates and the guest operating system can use more memory.
This technique optimizes memory usage and reduces the risk of memory exhaustion, making it useful in cloud computing environments. However, it also has trade-offs to consider. Inflating the balloon driver can cause performance issues if the guest operating system can’t release memory quickly enough. It may also struggle with high memory pressure. Understanding these limitations is key to making informed decisions about using virtio memory ballooning.
Overview of Virtio Memory Ballooning
Based on wiki memory ballooning is a technique used to eliminate the need to overprovision host memory used by a virtual machine. To implement it, the virtual machine’s kernel implements a “balloon driver” which allocates unused memory within the VM’s address space into a reserved memory pool (the “balloon”) so that it is unavailable to other processes on the VM. However, rather than being reserved for other uses within the VM, the physical memory mapped to those pages within the VM is actually unmapped from the VM by the host operating system’s hypervisor, making it available for other uses by the host machine. Depending on the amount of memory required by the VM, the size of the “balloon” may be increased or decreased dynamically, mapping and unmapping physical memory as required by the VM.
According to the Virtio v1.2 specification, Virtio Memory Ballooning follows the Virtio protocol. Including:
Feature bits
VIRTIO_BALLOON_F_MUST_TELL_HOST (0): Host must be notified before balloon pages are used.
VIRTIO_BALLOON_F_STATS_VQ (1): A virtqueue is present for reporting guest memory statistics.
VIRTIO_BALLOON_F_DEFLATE_ON_OOM (2): Balloon deflates when guest is out of memory.
VIRTIO_BALLOON_F_FREE_PAGE_HINT (3): The device supports free page hinting. The configuration field free_page_hint_cmd_id is valid.
VIRTIO_BALLOON_F_PAGE_POISON (4): The driver will immediately write poison_val to pages after deflating them. The configuration field poison_val is valid.
VIRTIO_BALLOON_F_PAGE_REPORTING (5): The device supports free page reporting. A virtqueue is present for reporting free guest memory.
Memory Statistics Tags
VIRTIO_BALLOON_S_SWAP_IN (0): Amount of memory swapped in (in bytes).
VIRTIO_BALLOON_S_SWAP_OUT (1): Amount of memory swapped out to disk (in bytes).
VIRTIO_BALLOON_S_MAJFLT (2): Number of major page faults that have occurred.
VIRTIO_BALLOON_S_MINFLT (3): Number of minor page faults that have occurred.
VIRTIO_BALLOON_S_MEMFREE (4): Amount of memory not being used (in bytes).
VIRTIO_BALLOON_S_MEMTOT (5): Total amount of memory available (in bytes).
VIRTIO_BALLOON_S_AVAIL (6): Estimate of available memory (in bytes) for starting new applications.
VIRTIO_BALLOON_S_CACHES (7): Amount of memory (in bytes) that can be quickly reclaimed without I/O.
VIRTIO_BALLOON_S_HTLB_PGALLOC (8): Number of successful hugetlb page allocations in the guest.
VIRTIO_BALLOON_S_HTLB_PGFAIL (9): Number of failed hugetlb page allocations in the guest.
Free page hinting
Free page hinting is used during migration to determine which pages within the guest are not being used. These pages are then skipped over while migrating the guest. The device will indicate it is ready to start hinting by setting the free_page_hint_cmd_id to one of the non-reserved values that can be used as a command ID. The driver is notified of the following reserved values:
VIRTIO_BALLOON_CMD_ID_STOP (0): any previously supplied command ID is invalid. The driver should stop hinting free pages until a new command ID is supplied, but should not release any hinted pages for use by the guest.
VIRTIO_BALLOON_CMD_ID_DONE (1): any previously supplied command ID is invalid. The driver should stop hinting free pages and release all hinted pages for use by the guest.
When a hint is provided, it indicates that the data contained in the given page is no longer needed and can be discarded. If the driver writes to the page, this overrides the hint and the data will be retained. Any stale pages that have not been written to since the page was hinted may lose their content. If read, the contents of such pages will be uninitialized memory.
Page Poison
Page Poison is a feature that lets the host know when the guest is initializing free pages with poison_val. When enabled, the driver immediately writes to pages after deflating and pages reported as free will retain poison_val. If the guest is not initializing freed pages, the driver should reject the VIRTIO_BALLOON_F_PAGE_POISON feature. If the feature has been negotiated, the driver will place the initialization value into the poison_val configuration field data.
Free Page Reporting
Free Page Reporting is a method similar to balloon inflation, but without a deflation queue. Reported free pages can be reused by the driver after the request is acknowledged, without notifying the device.
The driver initiates reporting by gathering free pages into a scatter-gather list, which is then added to the reporting_vq. The exact timing and selection of free pages is determined by the driver.
Once the driver has enough pages available, it sends a reporting request to the device, which acknowledges the request using the reporting_vq descriptor. After acknowledgement, the driver can reuse the reported free pages by returning them to the free page lists in the guest operating system.
The driver can continue to gather and report free pages until it has reached the desired number of pages.
Comparison to Other Memory Management Techniques
Virtio memory ballooning is just one of several memory management techniques available in virtualized environments. Here are some other techniques that are commonly used:
Overcommitment
Overcommitment is a technique that allows virtual machines to use more memory than physically available. This is useful when memory demand is highly variable. However, overcommitment can cause performance issues if the host system runs out of memory and needs to swap memory pages to disk.
KVM hypervisor automatically overcommits CPUs and memory. This means that more virtualized CPUs and memory can be allocated to virtual machines than there are physical resources. This saves system resources, resulting in less power, cooling, and investment in server hardware while still allowing under-utilized virtualized servers or desktops to run on fewer hosts.
Memory Compression
Memory compression compresses memory pages to free up memory in high demand situations. However, this technique can lead to performance problems if the compression algorithm is slow or if memory demand is high.
Zram, zcache, and zswap advance in-kernel compression in different ways. Zram and zcache, both found in the staging tree, have improved in design and implementation, but they are not stable enough for promotion into the core kernel. Zswap proposes a simplified frontswap-only fork of zcache for direct merging into the MM subsystem. While simpler than zcache, zswap is entirely dependent on still-in-staging zsmalloc and has limitations. If zswap is merged, it remains to be seen if it will ever be extended adequately.
Hypervisor Swapping
Hypervisor swapping is a technique in which the hypervisor swaps memory pages between the host and guest operating systems in order to optimize memory usage. This can be useful in situations where there is a high demand for memory or when the host system is running low on memory. However, hypervisor swapping can also lead to performance issues if the guest operating system can’t release memory quickly enough.
Compared to these techniques, virtio memory ballooning has some unique advantages. It optimizes memory usage within the guest operating system itself, reducing the risk of memory exhaustion and improving performance. However, it also has some trade-offs to consider, such as the potential for performance issues if the guest operating system can’t release memory quickly enough.
How to use Virtio Memory Ballooning on linux
Environment
On host side we use libvirt to setup a vm.
The memory tag means: The maximum allocation of memory for the guest at boot time.
The currentMemory tag means: The actual allocation of memory for the guest.
To use Virtio Memory Ballooning on Linux guest, you’ll need to ensure that your kernel has support for the virtio_balloon driver. You can check for this by running the following command:
1
lsmod | grep virtio_balloon
If the virtio_balloon driver is not listed, you may need to load it manually by running the following command:
1
modprobe virtio_balloon
We can do some test to confirm balloon driver is working:
# virsh dommemstat YOUR_VM_NAME actual 8388608 # Current balloon value (in KB) swap_in 7011156 # The amount of data read from swap space (in kB) swap_out 664776 # The amount of memory written out to swap space (in kB) major_fault 234565 # The number of page faults where disk IO was required minor_fault 84722778 # The number of other page faults unused 6291308 # The amount of memory left unused by the system (in kB) available 8388044 # The amount of usable memory as seen by the domain (in kB) usable 6349618 # The amount of memory which can be reclaimed by balloon without causing host swapping (in KB) * last_update 1682566755 # Timestamp of the last update of statistics (in seconds) disk_caches 116620 # The amount of memory that can be reclaimed without additional I/O, typically disk caches (in KiB) rss 8529188 # Resident Set Size of the running domain's process (in kB)
with memory balloon we can get details about guest usage which matches the Memory Statistics Tags we metioned above.
And from dominfo we can see the memory usage directly
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# virsh dominfo YOUR_VM_NAME Id: 7 Name: 1970b0ef25e44adc834767fe81f155d5 UUID: 1970b0ef-25e4-4adc-8347-67fe81f155d5 OS Type: hvm State: running CPU(s): 4 CPU time: 214084.1s Max memory: 8388608 KiB Used memory: 8388608 KiB Persistent: yes Autostart: disable Managed save: no Security model: none Security DOI: 0
actual changed to 5519904 and we check the guest on the other side
1 2 3 4
# free -hm total used free shared buff/cache available Mem: 4.9G 862M 134M 299M 3.9G 3.3G Swap: 7.9G 3.5M 7.9G
Total memory changed even smaller than 5519904 ~= 5.26G about 7% memory missing and almost same with available 5139400
Expanding memory
To increase the memory allocation of a virtual machine using virtio memory ballooning, you can use the virsh setmem command. For example, to increase the memory allocation to 8GB, you would run:
1
virsh setmem YOUR_VM_NAME --size 8G --current
This will increase the memory allocation of the virtual machine to 8GB. However, it’s important to note that the guest operating system must have support for virtio memory ballooning in order to take advantage of this feature.
In addition, it’s important to monitor the memory usage of virtual machines to ensure that they have enough memory to operate effectively. This can be done using tools like virsh dommemstat to monitor memory usage statistics.
# free -hm total used free shared buff/cache available Mem: 7.6G 862M 2.9G 299M 3.9G 6.0G Swap: 7.9G 3.5M 7.9G
With 8GB memory from qemu side, guest have total 7.6G memory. There is still a 5% missing.
Industry Practices
Proxmox
Dynamic memory management shows that KSM and memory balloon works on windows and linux guest, a memory range from min and max will be required and guest’s memory will dynamicly changed between the range to impelement memory ballooning.
Google cloud
Dynamic resource management Memory ballooning is an interface mechanism between host and guest to dynamically adjust the size of the reserved memory for the guest. A virtio memory balloon device is used to implement memory ballooning. Through the virtio memory balloon device, a host can explicitly ask a guest to yield a certain amount of free memory pages (also called memory balloon inflation), and reclaim the memory so that the host can use the free memory for other VMs. Likewise, the virtio memory balloon device can return memory pages back to the guest by deflating the memory balloon.
Compute Engine E2 VM instances that are based on a public image have a virtio memory balloon device , which monitors the guest operating system’s memory use. The guest operating system communicates its available memory to the host system. The host reallocates any unused memory to other processes on demand, thereby using memory more effectively. Compute Engine collects and uses this data to make more accurate rightsizing recommendations.
In Linux kernels before 5.2, the Linux memory system sometimes mistakenly prevents large allocations when the balloon device is present. This is rarely an issue in practice, but we recommend changing the virtual memory overcommit_memory setting to 1 to prevent the issue from occurring. This change is already made by default in all Google-provided images published since February 9, 2021.
To fix the setting, use the following command to change the value from 0 to 1:
1
sudo /sbin/sysctl -w vm.overcommit_memory=1
To persist this change across reboots, add the following to your /etc/sysctl.conf file:
Memory overcommit allows more memory to be assigned to VMs than is physically present in the server hardware. Unused memory allocated to a VM can be reclaimed by the hypervisor and made available to other VMs on the host. AHV adjusts memory usage for each VM according to its usage, allowing the host to use excess memory to satisfy the requirements of other VMs. This reduces hardware costs for large deployments or increases the utilization of an existing environment that can’t be immediately expanded with new nodes. VMs without memory overcommit will operate with their pre-assigned memory, and can coexist with overcommit enabled VMs. Nutanix uses a multi-tier approach combining ballooning and hypervisor-level swap to optimize performance. Metrics are presented to the administrator in Prism Central to indicate the gains achieved through overcommit and its impact on VM performance. Memory overcommit may not be appropriate for performance-sensitive workloads due to its dynamic nature.
You can enable or disable Memory Overcommit only while the VM is powered off.
Power off the VM enabled with memory overcommit before you change the memory allocation for the VM. For example, you cannot update the memory of a VM that is enabled with memory overcommit when it is still running. The system displays the following alert: InvalidVmState: Cannot complete request in state on.
Memory overcommit is not supported with VMs that use GPU passthrough and vNUMA. For example, you cannot update a VM to a vNUMA VM when it is enabled with memory overcommit. The system displays the following alert: InvalidArgument: Cannot use memory overcommit feature for a vNUMA VM error.
Memory overcommit feature can slow down the performance and the predictable performance of the VM For example, migrating a VM enabled with Memory Overcommit takes longer than migrating a VM not enabled with Memory Overcommit.
There may be a temporary spike in the aggregate memory usage in the cluster during the migration of a VM enabled with Memory Overcommit from one node to another. For example, when you migrate a VM from Node A to Node B, the total memory used in the cluster during migration is greater than the memory usage before the migration. The memory usage of the cluster eventually drops back to pre-migration levels when the cluster reclaims the memory for other VM operations.
Using Memory Overcommit heavily can cause a spike in the disk space utilization in the cluster. This spike is caused because the Host Swap uses some of the disk space in the cluster. If the VMs do not have a swap disk, then in case of memory pressure, AHV uses space from the swap disk created on ADSF to provide memory to the VM. This can lead to an increase in disk space consumption on the cluster.
All DR operations except Cross Cluster Live Migration (CCLM) are supported On the destination side, if a VM fails when you enable Memory Overcommit, the failed VM fails over (creating the VM on the remote site) as a fixed size VM. You can enable Memory Overcommit on this VM after the failover is complete.
Limitations and Challenges
Guest should support virtio memory ballooning, if the balloon driver not available there is no effective way to do it.
Distribution
No Balloon Driver
Partially Supported
Fully Supported
CentOS
6.1, 6.2
6.3–6.9, 7.1, 7.2
7.3–7.7, 8.0–8.2
Oracle
7.3
7.4, 7.5
7.6, 7.7
Ubuntu
See note.
12.04
14.04 and newer
Not all situations are suitable for memory ballooning. Frequent expansion and contraction of memory can be harmful if the memory usage changes dynamically.
Virtualization is important in modern computing for flexible and efficient resource allocation. Memory management is challenging in virtualized environments when multiple virtual machines run on a single physical server. Virtio memory ballooning optimizes memory usage by dynamically adjusting guest memory reservation. It improves performance and reduces the risk of memory exhaustion. This article explains how to use virtio memory ballooning on Linux, compares it to other memory management techniques, and discusses industry practices, limitations, and future developments.
Based on the code design of blkverify.c and blkmirror.c, the main purpose is to mirror write requests to all the qcow images hanging in the quorum, and the read operation is to check whether the number of occurrences of the qiov version meets the value set by the threshold through the parameters set by the threshold. Then it returns the > value of the result with the highest number of occurrences, if the number of occurrences i is less than the threshold then it returns the quourm exception and the read operation returns -EIO.
The main use of this feature is for people who use NFS devices affected by bitflip errors.
If you set the read-pattern to FIFO and set the threshold to 1, you can construct a read-only first disk scenario.
block-replication
The micro checkpoint and COLO mentioned in the introduction to the QEMU FT solution will continuously create checkpoints, and the state of the pvm and svm will be the same at the moment the checkpoint is completed. But it will not be consistent until the next checkpoint.
To ensure consistency, the SVM changes need to be cached and discarded at the next checkpoint. To reduce the stress of network transfers between checkpoints, changes on the PVM disk are synchronized asynchronously to the SVM node.
For example, the first time VM1 does a checkpoint, it is recorded as state C1, then VM2’s state is also C1, at this time VM2’s disk changes start to cache, VM1’s changes are written to VM2’s node through this mechanism, if an error occurs at this time how should it be handled?
Suppose we discuss the simplest case of VM1 hanging, then because the next checkpoint has not yet been executed, VM2 continues to run the state of C1 for a period of time and the disk changes are cached, at this time it is only necessary to flush the cached data to VM2’s disk single point to continue to run or wait for FT reconstruction, which is the reason for the need to do SVM disk changes caching (here the data (including two copies, one is to restore to VM2 last checkpoint cache, the other is to VM2 in C1 after the cache of changes)
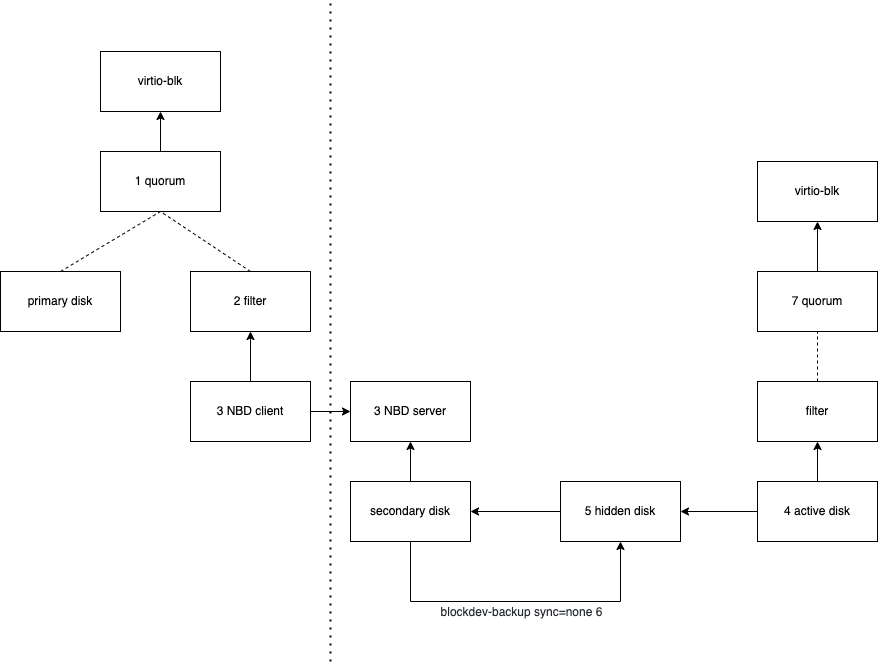
The following is the structure of block-replication:
The block device on the primary node mounts two sub-devices via quorum, providing backup from the primary node to the secondary host. The read pattern (FIFO) is extended to meet the situation where the primary node will only read the local disk (the threshold needs to be set to 1 so that read operations will only be performed locally)
A newly implemented filter called replication is responsible for controlling block replication
The secondary node receives disk write requests from the primary node through the embedded nbd server
The device on the secondary node is a custom block device, we call it an active disk. it should be an empty device at the beginning, but the block device needs to support bdrv_make_empty() and backing_file
The hidden-disk is created automatically, and this file caches the contents modified by what is written from the primary node. It should also be an empty device at the beginning and support bdrv_make_empty() and backing_file
The blockdev-backup job (sync=none) will synchronize all the contents of the hidden-disk cache that should have been overwritten by nbd-induced writes, so the primary and secondary nodes should have the same disk contents before the replication starts
The secondary node also has a quorum node, so that the secondary can become the new primary after the failover and continue to perform the replication
There are seven types of internal errors that can exist when block replication runs:
Primary disk I/O errors
Primary disk forwarding errors
blockdev-backup error
secondary disk I/O errors
active disk I/O error
Error clearing hidden disk and active disk
failover failure
For error 1 and error 5, just report block level errors directly upwards.
For 2, 3, 4, and 6 need to be reported to the control plane of FT for failover process control.
In the case of 7, if the active commit fails, it will prompt a secondary node write operation error and let the person performing the failover decide how to handle it.
colo checkpoint
colo uses vm’s live migration to achieve the checkpoint function
Based on the above block-replication to achieve disk synchronization, the other part is how to synchronize the running state data of virtual machines, here directly using the existing live migration, that is, cloud host hot migration, so that after each checkpoint can be considered pvm and svm disk/memory are consistent, so need to be in This event depends on the time of live migration.
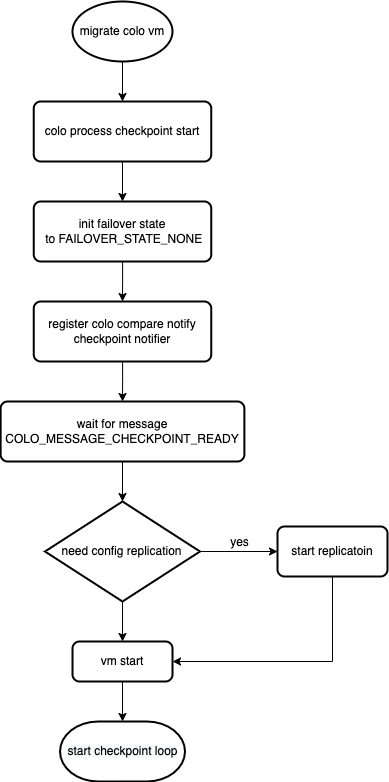
First, let’s organize the checkpoint process, which is divided into two major parts
Configuration phase
This part will be executed mainly when the colo is first set up, we know that by default at the beginning we will configure the disk synchronization of pvm and svm, but the memory is not actually synchronized yet, so at the beginning we will ask the svm to be pused at first after the startup, and then submit two synchronization operations from the pvm side
Submit the drive-mirror task to mirror the contents of the disk from the pvm to the remote svm’s disk (embedded nbd is used here, which is also the target disk of the block replicaton later) to ensure that the pvm’s contents are consistent with the svm’s
Submit a migration task to synchronize memory from pvm to svm, and since both pvm and svm are required to be paired at this point, you actually wait until both pvm and svm are synchronized, then you need to cancel the drive-mirror task, start block replication, and continue running vm Of course, the paused state mentioned in 2 has been changed to be similar to hot migration after the improvements made by intel. After the drive-mirror task is submitted, the id of the task and the information of the block replication disks are used as parameters for the colo migration, which will actually be automatically changed when migrating in the line of online migration. After the migration is completed, the drive-mirror task is automatically cancelled and block-replication is automatically started before running vm, which simplifies the steps a lot.
After the configuration, you need to manually issue a migrate command to the colo pvm, and the checkpoint will enter the cycle of monitoring after the first migrate.
Start the checkpoint
The checkpoint mechanism consists mainly of a loop, and the code flow of qemu is as follows:
Combined with this picture we explain the more important parts inside
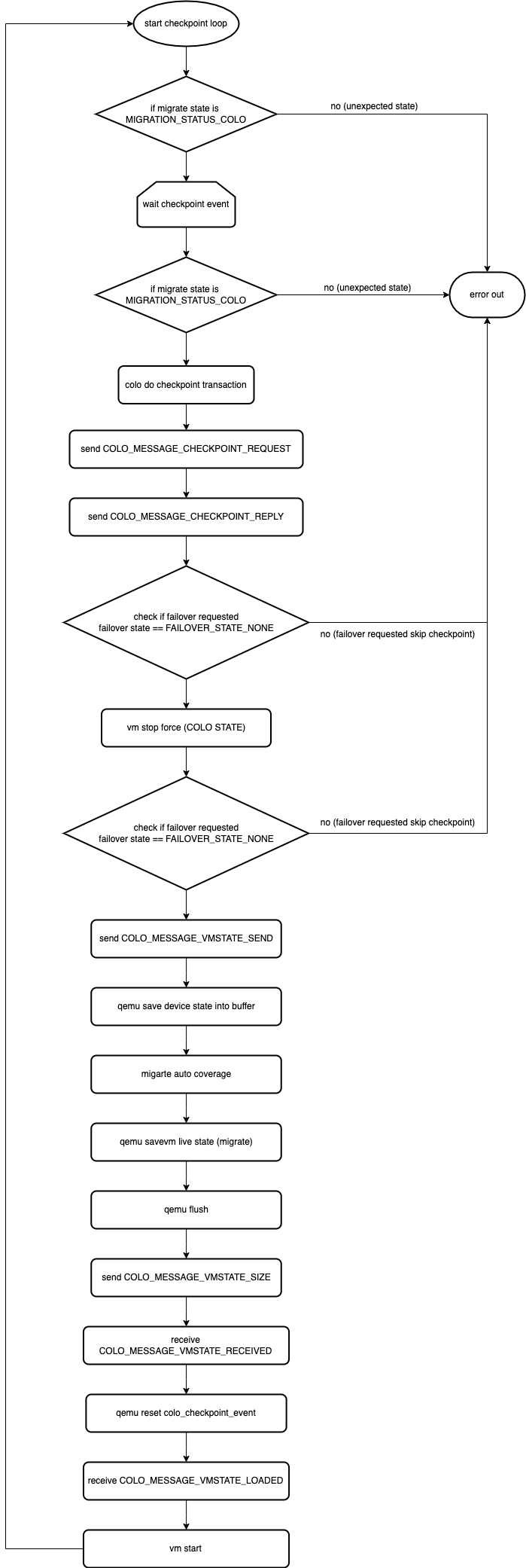
Process phase
COLO-FT initializes some key variables such as migration status, FAILOVER status and listens to the internal checkpoint notify (triggered from COLO compare)
After the first successful migrate, the discount state is initialized and the migration state is changed to COLO
After receiving a request for a checkpoint, a series of checkpoint creation processes are performed
Colo Status
For the COLO-FT virtual machine, there are two important states
One is the MigrationState, which on the COLO-FT virtual machine is MIGRATION_STATUS_COLO corresponding to the string “COLO”, which is a prerequisite state to allow checkpointing, and the cloud host must have established the COLO-FT mechanism. FT mechanism, that is, through the above configuration phase to complete the configuration and the first checkpoint, will enter this state and the main loop
Another state is failover_state, which is a global variable defined in colo_failover.c, which is accessed by colo.c through failover_get_state(), and this parameter is set to FAILOVER_STATUS at the start of the checkpoint loop _NONE, which means that failover is not needed. The bottom half of qemu mounts the mechanism for modifying this state, so it can be triggered by user state commands, so you need to pay attention to whether failover is triggered or not when actually doing checkpoint
Communitaion
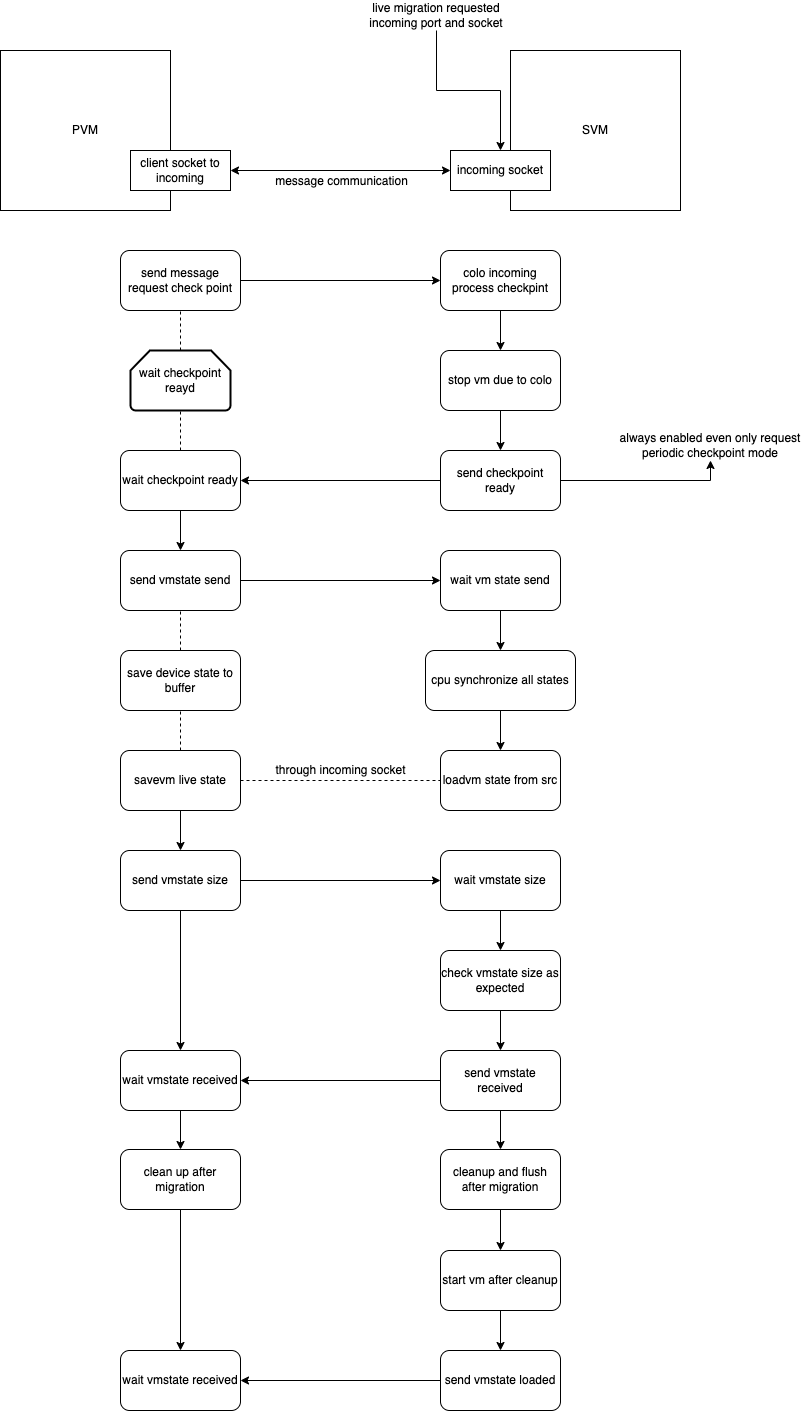
COLO communicates through messages to get the status of the SVM, as well as to send and confirm the start and completion of the checkpoint, and the message process inside has the following main steps
Sending COLO_MESSAGE_CHECKPOINT_REQUEST
After the SVM receives the message, pause the SVM and send COLO_MESSAGE_CHECKPOINT_READY
PVM starts saving and live migration of VMSTATE
SVM gets the migrated information and does the CPU synchronization and VM state LOAD locally.
SVM will wait for a check message from PVM after the migration is completed, and PVM will send a message after the live migration is completed.
PVM sends COLO_MESSAGE_VMSTATE_SIZE with the size of VMSTATE sent via QIOChannelBuffer
SVM receives the message and checks if the size received locally is the same as the size sent, if it is, it replies COLO_MESSAGE_VMSTATE_RECEIVED
After confirming the VMSTATE transfer, the SVM will do some migration and subsequent synchronization and cleanup.
After completion, the SVM executes vm_start() and sends COLO_MESSAGE_VMSTATE_LOADED.
After the PVM receives the message that the SVM has successfully loaded, the PVM will also execute vm_start().
The logic of suspend, migrate and resume the operation of PVM SVM is realized through the message collaboration between PVM and SVM
Existing problems, because the current checkpoint are notified to each other through the message, once the corresponding packet is sent and not returned, the next wait may always exist, can not be closed, assuming that at this time from the bottom half (bottom half) to send a request also did not do to clean up the wait state.
It should be noted that: the default checkpoint once the failure occurs, the vm will be a direct exit, requiring the rebuilding of COLO-FT, so the establishment of COLO-FT failure needs to be analyzed from two parts
Whether the configuration phase migration has failed Whether the configuration is complete (migration has become colo state) but the checkpoint failed (the above process failed) resulting in COLO-FT exit
colo proxy
colo proxy as the core component of COLO-FT, this article mainly focuses on the functionality of colo proxy in QEMU
When QEMU implements the net module, it actually treats the actual device in the guest as a receiver, so the corresponding relationship is as follows
TX RX
qemu side network device (sender) ——————-→ guest inside driver (receiver)
Combined with the code, the filter will be executed before actually doing transimission, and then go to sender processing.
NetQueue *queue; size_t size = iov_size(iov, iovcnt); int ret;
if (size > NET_BUFSIZE) { return size; }
if (sender->link_down || !sender->peer) { return size; }
/* Let filters handle the packet first */ ret = filter_receive_iov(sender, NET_FILTER_DIRECTION_TX, sender, QEMU_NET_PACKET_FLAG_NONE, iov, iovcnt, sent_cb); if (ret) { return ret; }
ret = filter_receive_iov(sender->peer, NET_FILTER_DIRECTION_RX, sender, QEMU_NET_PACKET_FLAG_NONE, iov, iovcnt, sent_cb); if (ret) { return ret; }
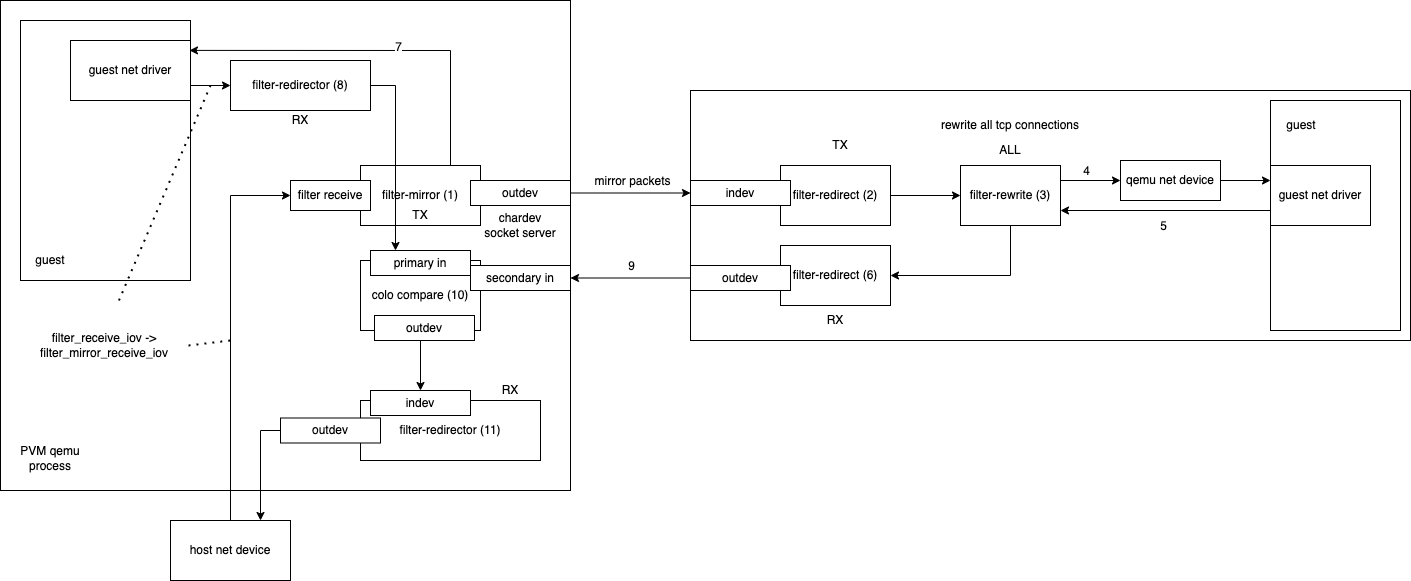
The filter-mirror and filter-redirect in the network-filter implemented by colo act as the forwarding function of the proxy
The classic process for a network card is as follows:
The host device receives the network packet and sends it to the guest
First execute the first filter-mirror, for qemu is transimission, so execute mirror action, the network packet mirror a copy sent off through outdev (chardev), and then call the next filter (because it is TX, so other filters will not be executed, so pvm on (the packet is sent directly to the guest)
SVM’s indev connects to PVM’s mirror’s outdev (via socket), so it receives the packet sent by 1. The filter does not specify an outdev after receiving the packet, so it calls the next filter directly
SVM calls filter-rewrite, the direction of this filter is ALL, so the packets to and from SVM will be processed by this filter, if the target is sent, because it is sent to VM so the first direction is TX, COLO will record the various states of this TCP packet
Because there is no next filter so it is sent to the qemu network device, and then take the process of sending to the guest
From the guest to the qemu network packet, the direction is RX so the filter processing order will be reversed and sent to the rewrite first
SVM calls filter-rewrite this time in the direction of RX, so when processing, it will process the tcp packets returned by SVM, compare the input and output of tcp packets through the tcp packets table, and if the processing fails, it will put the packet in the queue and resend it again (note: need to continue deeper analysis), and then the filter- redirector
Also in the PVM mirror filter, because there is no subsequent TX filter, the packet is sent directly to the qemu net device and then to the PVM guest.
The packets coming out of the PVM guest will be sent to the primary in interface of the colo-compare thing by filter-redirector because it is in the RX direction, so some filters will be performed in the reverse direction
SVM will send the return of SVM to the secondary in interface of colo-compare of PVM via redirector’s outdev colo-compare receives the packet and starts to do the relevant analysis to decide whether checkpoint is needed
The filter-redirector’s indev receives the return from colo-compare after comparison and forwards it to the host net device via outdev
This is the end of a complete packet processing process.
Since colo-compare is responsible for comparing pvm and svm packets, there are some metrics that need to be understood
payload
payload_size = total size - header_size i.e. the size of the whole packet minus the length of the header
packet data offset packet header size after the distance and payload_size comparison is consistent
The following is a summary of what needs to be done here
The logic of colo-compare comparison is organized:
Protocol
Action
TCP
Compare whether the payloads are the same. If it is the same and the ack is the same then it is over. If it is the same but the ack of pvm is larger than the ack of svm, the packet sent to svm is dropped and the packet of pvm will not be sent (meaning sent back to the host NIC). So we will record the maximum ack in the current queue (both pvm and svm queues) until the ack exceeds the smaller of the two maximum ack values, and we can ensure that the packet payload is confirmed by both sides
UDP
only palyload checked
ICMP
only palyload checked
Other
only packet size checked
Possible reasons for network packet loss are therefore:
colo-compare did not receive the packet correctly
svm’s redirector did not successfully forward packets to rewrite
mirror did not replicate the packet successfully
pvm’s redirector did not successfully send pvm’s return to colo-compare
svm’s rewrite did not send/receive packets successfully
colo-compare is not sending packets correctly
svm’s redirector did not successfully forward packets to colo-compare
Problem processing
The processing of 1 mainly relies on the colo compare mechanism itself, for tcp packets will determine whether there are subsequent packets returned by ack, if there are subsequent packets, it means that the previous is missed
2 If the packet is not successfully sent to rewrite, it will not be processed by svm, so finally colo compare will encounter the situation where pvm has a packet but svm does not have a packet, and the processing is similar to 1
3 If mirror does not successfully copy the package, then there will also be a situation similar to 1, pvm exists package, svm no package
4 if pvm redirector did not successfully send the packet, then it seems from colo compare is pvm lost packets, but the same 1 processing, will wait for the pvm and svm minimum ack is exceeded, that is, both pvm or svm even if packet loss occurs, colo compare will wait for the updated packet to appear before returning the packet otherwise will always card does not reverse the current packet
5 If rewritte’s send-receive fails, this situation will cause the svm to not receive the packet and not return, similar to 1, but if failover occurs at this time, the svm packet is lost
6 this exception will lead to colo send and receive packet exceptions, network anomalies, not very well handled because itself colo compare is the core component
7 similar situation svm seems to have replied or actively sent the packet, but because colo compare did not receive, resulting in the svm within the data that did not reply, the benefit is that if the subsequent failover can occur, rewrite because the packet was recorded, will send the packet again, then it seems to be working again (need to test)
Trigger checkpoint
There are two conditions for triggering from colo-comare, because COLO-FT will establish a notification mechanism when it is established, and colo compare will trigger checkpoint from inside actively through this mechanism
Checkpoint will be triggered if the payload of the compare tcp packet is inconsistent
Timed to check if there is a certain period of time but has not received the same return packet (i.e., pvm, svm packet chain table content is inconsistent) trigger checkpoint
If there is a packet in the pvm list but not in the secondary packet, then it means that the packet reply is late, this situation is handled by 2, if the comparison finds that the non-tcp packet comparison is inconsistent will trigger a checkpoint
Based on last blog, we can see how libvirt cpu feature configuration changes qemu cpuid. And we figure out hypervisor disable configuration have what kind of influence.
Then another recommanded feature from libvirt is kvm hidden. In the same way with last blog, we can find libvirt will configure kvm=off to -cpu and according to qemu:
those configures are defined by target/i386/cpu.c in variable x86_cpu_properties.
kvm=off will be treated as “kvm” is false and the local variable of this cpu changes expose_kvm to false.
1 2 3
if (!kvm_enabled() || !cpu->expose_kvm) { env->features[FEAT_KVM] = 0; }
x86_cpu_realizefn will invoke x86_cpu_expand_features to expand features from configuration, as a result FEAT_KVM will disable all features after realize features.
/* This CPUID returns a feature bitmap in eax. Before enabling a particular * paravirtualization, the appropriate feature bit should be checked. */ #define KVM_CPUID_FEATURES 0x40000001 #define KVM_FEATURE_CLOCKSOURCE 0 #define KVM_FEATURE_NOP_IO_DELAY 1 #define KVM_FEATURE_MMU_OP 2 /* This indicates that the new set of kvmclock msrs * are available. The use of 0x11 and 0x12 is deprecated */ #define KVM_FEATURE_CLOCKSOURCE2 3 #define KVM_FEATURE_ASYNC_PF 4 #define KVM_FEATURE_STEAL_TIME 5 #define KVM_FEATURE_PV_EOI 6 #define KVM_FEATURE_PV_UNHALT 7
/* The last 8 bits are used to indicate how to interpret the flags field * in pvclock structure. If no bits are set, all flags are ignored. */ #define KVM_FEATURE_CLOCKSOURCE_STABLE_BIT 24
And before we check all features details let’s check how linux figure kvm feature at first.
function: define KVM_CPUID_FEATURES (0x40000001) returns : ebx, ecx, edx = 0 eax = and OR'ed group of (1 << flag), where each flags is:
flag || value || meaning ============================================================================= KVM_FEATURE_CLOCKSOURCE || 0 || kvmclock available at msrs || || 0x11 and 0x12. ------------------------------------------------------------------------------ KVM_FEATURE_NOP_IO_DELAY || 1 || not necessary to perform delays || || on PIO operations. ------------------------------------------------------------------------------ KVM_FEATURE_MMU_OP || 2 || deprecated. ------------------------------------------------------------------------------ KVM_FEATURE_CLOCKSOURCE2 || 3 || kvmclock available at msrs || || 0x4b564d00 and 0x4b564d01 ------------------------------------------------------------------------------ KVM_FEATURE_ASYNC_PF || 4 || async pf can be enabled by || || writing to msr 0x4b564d02 ------------------------------------------------------------------------------ KVM_FEATURE_STEAL_TIME || 5 || steal time can be enabled by || || writing to msr 0x4b564d03. ------------------------------------------------------------------------------ KVM_FEATURE_PV_EOI || 6 || paravirtualized end of interrupt || || handler can be enabled by writing || || to msr 0x4b564d04. ------------------------------------------------------------------------------ KVM_FEATURE_PV_UNHALT || 7 || guest checks this feature bit || || before enabling paravirtualized || || spinlock support. ------------------------------------------------------------------------------ KVM_FEATURE_CLOCKSOURCE_STABLE_BIT || 24 || host will warn if no guest-side || || per-cpu warps are expected in || || kvmclock. ------------------------------------------------------------------------------
/* * Set the IDT descriptor to a fixed read-only location, so that the * "sidt" instruction will not leak the location of the kernel, and * to defend the IDT against arbitrary memory write vulnerabilities. * It will be reloaded in cpu_init() */ __set_fixmap(FIX_RO_IDT, __pa_symbol(idt_table), PAGE_KERNEL_RO); idt_descr.address = fix_to_virt(FIX_RO_IDT);
/* * Should be a barrier for any external CPU state: */ cpu_init();
src = &per_cpu(steal_time, cpu); do { version = src->version; rmb(); steal = src->steal; rmb(); } while ((version & 1) || (version != src->version));
return steal; }
which will steal the time from cpu directly.
KVM_FEATURE_PV_EOI
From kvm guest init:
1 2
if (kvm_para_has_feature(KVM_FEATURE_PV_EOI)) apic_set_eoi_write(kvm_guest_apic_eoi_write);
During kvm guest cpu init:
1 2 3 4 5 6 7 8 9
if (kvm_para_has_feature(KVM_FEATURE_PV_EOI)) { unsignedlong pa; /* Size alignment is implied but just to make it explicit. */ BUILD_BUG_ON(__alignof__(kvm_apic_eoi) < 4); __this_cpu_write(kvm_apic_eoi, 0); pa = slow_virt_to_phys(this_cpu_ptr(&kvm_apic_eoi)) | KVM_MSR_ENABLED; wrmsrl(MSR_KVM_PV_EOI_EN, pa); }
Besides, those paravirt kvm features is used by kernel so those features need to be disabled if kernel changed, for example, load kernel by kexec, to avoid the features pointing to old memory of old kernel, those features will disabled by write msr manually:
1 2 3 4 5 6 7 8 9 10 11 12
staticvoidkvm_pv_guest_cpu_reboot(void *unused) { /* * We disable PV EOI before we load a new kernel by kexec, * since MSR_KVM_PV_EOI_EN stores a pointer into old kernel's memory. * New kernel can re-enable when it boots. */ if (kvm_para_has_feature(KVM_FEATURE_PV_EOI)) wrmsrl(MSR_KVM_PV_EOI_EN, 0); kvm_pv_disable_apf(); kvm_disable_steal_time(); }
That’s all due to paravirt use shared memory to use those features between guest and host.
KVM_FEATURE_PV_UNHALT
Allow to use para-virtualized spinlock
1 2 3 4 5 6 7 8
void __init kvm_spinlock_init(void) { if (!kvm_para_available()) return; /* Does host kernel support KVM_FEATURE_PV_UNHALT? */ if (!kvm_para_has_feature(KVM_FEATURE_PV_UNHALT)) return;
KVM_FEATURE_CLOCKSOURCE_STABLE_BIT
kvm clock will set a PVCLOCK_TSC_STABLE_BIT to pvclock.
1 2 3 4 5
printk(KERN_INFO "kvm-clock: Using msrs %x and %x", msr_kvm_system_time, msr_kvm_wall_clock);
if (kvm_para_has_feature(KVM_FEATURE_CLOCKSOURCE_STABLE_BIT)) pvclock_set_flags(PVCLOCK_TSC_STABLE_BIT);
do { version = pvclock_read_begin(src); ret = __pvclock_read_cycles(src, rdtsc_ordered()); flags = src->flags; } while (pvclock_read_retry(src, version));
kvm_guest_time_update -> kvm_make_request(KVM_REQ_CLOCK_UPDATE, v); first update is from kvm request:
1 2 3 4 5
if (kvm_check_request(KVM_REQ_CLOCK_UPDATE, vcpu)) { r = kvm_guest_time_update(vcpu); if (unlikely(r)) goto out; }
then interrupt will be disabled to prevent clock changes:
1 2 3 4 5 6 7 8
/* Keep irq disabled to prevent changes to the clock */ local_irq_save(flags); this_tsc_khz = __this_cpu_read(cpu_tsc_khz); if (unlikely(this_tsc_khz == 0)) { local_irq_restore(flags); kvm_make_request(KVM_REQ_CLOCK_UPDATE, v); return1; }
INIT_DELAYED_WORK(&kvm->arch.kvmclock_update_work, kvmclock_update_fn); -> kvmclock_update_fn -> kvm_make_request(KVM_REQ_CLOCK_UPDATE, v); kvm lock will be updated by a schedule:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* * kvmclock updates which are isolated to a given vcpu, such as * vcpu->cpu migration, should not allow system_timestamp from * the rest of the vcpus to remain static. Otherwise ntp frequency * correction applies to one vcpu's system_timestamp but not * the others. * * So in those cases, request a kvmclock update for all vcpus. * We need to rate-limit these requests though, as they can * considerably slow guests that have a large number of vcpus. * The time for a remote vcpu to update its kvmclock is bound * by the delay we use to rate-limit the updates. */
kvm_arch_vcpu_load update clock if no master clock or host cpu to sync.
1 2 3 4 5 6 7 8 9
/* * On a host with synchronized TSC, there is no need to update * kvmclock on vcpu->cpu migration */ if (!vcpu->kvm->arch.use_master_clock || vcpu->cpu == -1) kvm_make_request(KVM_REQ_GLOBAL_CLOCK_UPDATE, vcpu); if (vcpu->cpu != cpu) kvm_migrate_timers(vcpu); vcpu->cpu = cpu;
kvm_arch_vcpu_load -> kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); Adjust time if needed
1 2 3 4 5 6
/* Apply any externally detected TSC adjustments (due to suspend) */ if (unlikely(vcpu->arch.tsc_offset_adjustment)) { adjust_tsc_offset_host(vcpu, vcpu->arch.tsc_offset_adjustment); vcpu->arch.tsc_offset_adjustment = 0; kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); }
kvm_set_guest_paused -> kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); if guest kernel stopped by hypervisor use this to update pv clock.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
/* * kvm_set_guest_paused() indicates to the guest kernel that it has been * stopped by the hypervisor. This function will be called from the host only. * EINVAL is returned when the host attempts to set the flag for a guest that * does not support pv clocks. */ staticintkvm_set_guest_paused(struct kvm_vcpu *vcpu) { if (!vcpu->arch.pv_time_enabled) return -EINVAL; vcpu->arch.pvclock_set_guest_stopped_request = true; kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); return0; }
kvmclock_cpufreq_notifier -> kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); see the annotation from code:
/* * We allow guests to temporarily run on slowing clocks, * provided we notify them after, or to run on accelerating * clocks, provided we notify them before. Thus time never * goes backwards. * * However, we have a problem. We can't atomically update * the frequency of a given CPU from this function; it is * merely a notifier, which can be called from any CPU. * Changing the TSC frequency at arbitrary points in time * requires a recomputation of local variables related to * the TSC for each VCPU. We must flag these local variables * to be updated and be sure the update takes place with the * new frequency before any guests proceed. * * Unfortunately, the combination of hotplug CPU and frequency * change creates an intractable locking scenario; the order * of when these callouts happen is undefined with respect to * CPU hotplug, and they can race with each other. As such, * merely setting per_cpu(cpu_tsc_khz) = X during a hotadd is * undefined; you can actually have a CPU frequency change take * place in between the computation of X and the setting of the * variable. To protect against this problem, all updates of * the per_cpu tsc_khz variable are done in an interrupt * protected IPI, and all callers wishing to update the value * must wait for a synchronous IPI to complete (which is trivial * if the caller is on the CPU already). This establishes the * necessary total order on variable updates. * * Note that because a guest time update may take place * anytime after the setting of the VCPU's request bit, the * correct TSC value must be set before the request. However, * to ensure the update actually makes it to any guest which * starts running in hardware virtualization between the set * and the acquisition of the spinlock, we must also ping the * CPU after setting the request bit. * */
after kvm_guest_exit(); update clock if vcpu request clock always up to date.
1 2
if (unlikely(vcpu->arch.tsc_always_catchup)) kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu);
hardware_enable_nolock -> kvm_arch_hardware_enable -> kvm_make_request(KVM_REQ_CLOCK_UPDATE, vcpu); multi functino access hardware_enable_nolock
kvm_cpu_hotplug
1 2 3 4 5 6 7 8 9 10 11 12 13 14
staticintkvm_cpu_hotplug(struct notifier_block *notifier, unsignedlong val, void *v) { val &= ~CPU_TASKS_FROZEN; switch (val) { case CPU_DYING: hardware_disable(); break; case CPU_STARTING: hardware_enable(); break; } return NOTIFY_OK; }
kvm_resume
Note: for hv_stimer
1 2 3 4 5 6 7
/* * KVM_REQ_HV_STIMER has to be processed after * KVM_REQ_CLOCK_UPDATE, because Hyper-V SynIC timers * depend on the guest clock being up-to-date */ if (kvm_check_request(KVM_REQ_HV_STIMER, vcpu)) kvm_hv_process_stimers(vcpu);
will be done after guest clock up-to-date.
Hyper-v impact conclusion
With kvm hidden, hyper-v tsc compute will be skipped:
staticvoidkvmclock_vm_state_change(void *opaque, int running, RunState state) { KVMClockState *s = opaque; CPUState *cpu; int cap_clock_ctrl = kvm_check_extension(kvm_state, KVM_CAP_KVMCLOCK_CTRL); int ret;
if (running) { structkvm_clock_datadata = {};
/* * If the host where s->clock was read did not support reliable * KVM_GET_CLOCK, read kvmclock value from memory. */ if (!s->clock_is_reliable) { uint64_t pvclock_via_mem = kvmclock_current_nsec(s); /* We can't rely on the saved clock value, just discard it */ if (pvclock_via_mem) { s->clock = pvclock_via_mem; } }
s->clock_valid = false;
data.clock = s->clock; ret = kvm_vm_ioctl(kvm_state, KVM_SET_CLOCK, &data); if (ret < 0) { fprintf(stderr, "KVM_SET_CLOCK failed: %s\n", strerror(ret)); abort(); }
kvm_update_clock(s); /* * If the VM is stopped, declare the clock state valid to * avoid re-reading it on next vmsave (which would return * a different value). Will be reset when the VM is continued. */ s->clock_valid = true; } }
when set guest to running, qemu will use KVM_SET_CLOCK else will use kvm_update_clock works as following:
staticvoidkvm_update_clock(KVMClockState *s) { structkvm_clock_datadata; int ret;
ret = kvm_vm_ioctl(kvm_state, KVM_GET_CLOCK, &data); if (ret < 0) { fprintf(stderr, "KVM_GET_CLOCK failed: %s\n", strerror(ret)); abort(); } s->clock = data.clock;
/* If kvm_has_adjust_clock_stable() is false, KVM_GET_CLOCK returns * essentially CLOCK_MONOTONIC plus a guest-specific adjustment. This * can drift from the TSC-based value that is computed by the guest, * so we need to go through kvmclock_current_nsec(). If * kvm_has_adjust_clock_stable() is true, and the flags contain * KVM_CLOCK_TSC_STABLE, then KVM_GET_CLOCK returns a TSC-based value * and kvmclock_current_nsec() is not necessary. * * Here, however, we need not check KVM_CLOCK_TSC_STABLE. This is because: * * - if the host has disabled the kvmclock master clock, the guest already * has protection against time going backwards. This "safety net" is only * absent when kvmclock is stable; * * - therefore, we can replace a check like * * if last KVM_GET_CLOCK was not reliable then * read from memory * * with * * if last KVM_GET_CLOCK was not reliable && masterclock is enabled * read from memory * * However: * * - if kvm_has_adjust_clock_stable() returns false, the left side is * always true (KVM_GET_CLOCK is never reliable), and the right side is * unknown (because we don't have data.flags). We must assume it's true * and read from memory. * * - if kvm_has_adjust_clock_stable() returns true, the result of the && * is always false (masterclock is enabled iff KVM_GET_CLOCK is reliable) * * So we can just use this instead: * * if !kvm_has_adjust_clock_stable() then * read from memory */ s->clock_is_reliable = kvm_has_adjust_clock_stable(); }
But from the annotation in kvmclock_vm_state_change:
1 2 3 4 5
/* * If the VM is stopped, declare the clock state valid to * avoid re-reading it on next vmsave (which would return * a different value). Will be reset when the VM is continued. */
qemu seems to relay on vmsave to reset the guest while vm is continued, we just keep our eyes on that.
case KVM_SET_CLOCK: { structkvm_arch *ka = &kvm->arch; structkvm_clock_datauser_ns; u64 now_ns;
r = -EFAULT; if (copy_from_user(&user_ns, argp, sizeof(user_ns))) goto out;
r = -EINVAL; if (user_ns.flags) goto out;
r = 0; /* * TODO: userspace has to take care of races with VCPU_RUN, so * kvm_gen_update_masterclock() can be cut down to locked * pvclock_update_vm_gtod_copy(). */ kvm_gen_update_masterclock(kvm);
/* * This pairs with kvm_guest_time_update(): when masterclock is * in use, we use master_kernel_ns + kvmclock_offset to set * unsigned 'system_time' so if we use get_kvmclock_ns() (which * is slightly ahead) here we risk going negative on unsigned * 'system_time' when 'user_ns.clock' is very small. */ spin_lock_irq(&ka->pvclock_gtod_sync_lock); if (kvm->arch.use_master_clock) now_ns = ka->master_kernel_ns; else now_ns = get_kvmclock_base_ns(); ka->kvmclock_offset = user_ns.clock - now_ns; spin_unlock_irq(&ka->pvclock_gtod_sync_lock);
/* * Fall back to get_kvmclock_ns() when TSC page hasn't been set up, * is broken, disabled or being updated. */ if (hv->hv_tsc_page_status != HV_TSC_PAGE_SET) return div_u64(get_kvmclock_ns(kvm), 100);
/* * To simplify handling the periodic timer, leave the hv timer running * even if the deadline timer has expired, i.e. rely on the resulting * VM-Exit to recompute the periodic timer's target expiration. */ if (!apic_lvtt_period(apic)) { /* * Cancel the hv timer if the sw timer fired while the hv timer * was being programmed, or if the hv timer itself expired. */ if (atomic_read(&ktimer->pending)) { cancel_hv_timer(apic); } elseif (expired) { apic_timer_expired(apic, false); cancel_hv_timer(apic); } }
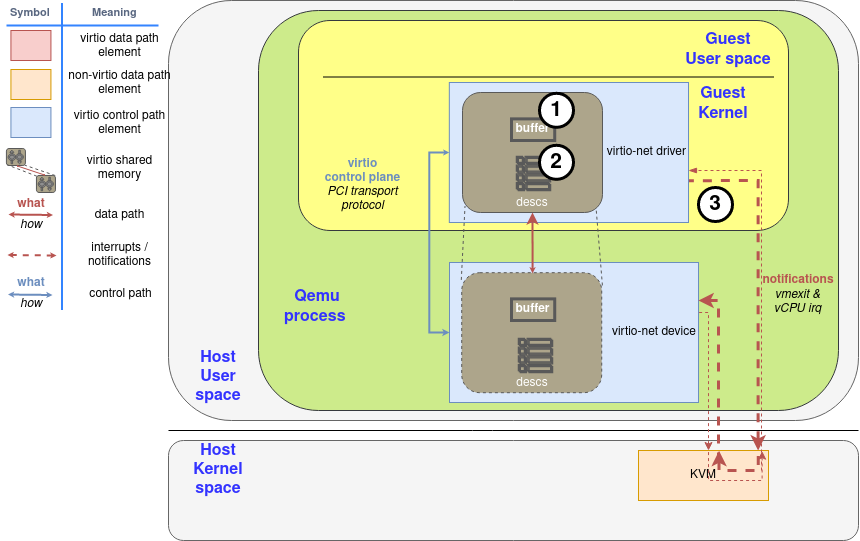
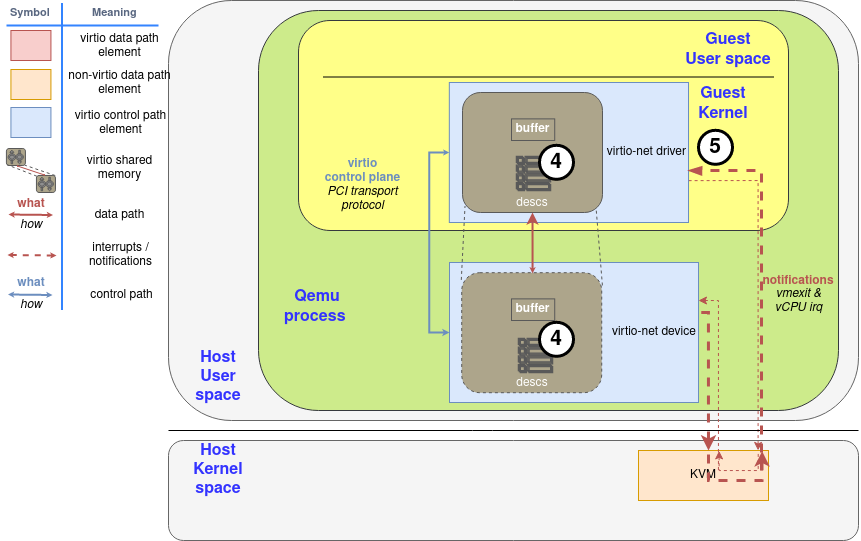
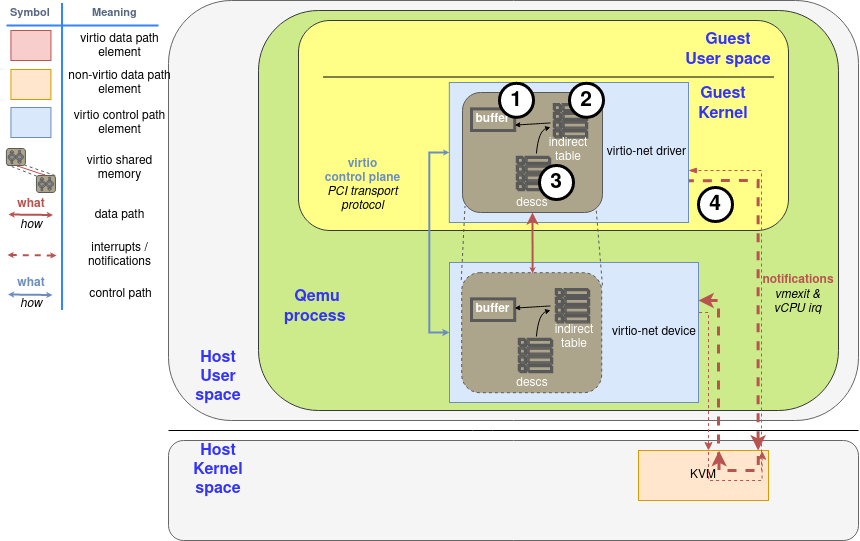
Virtio is an open standard that defines a protocol for communication between drivers and devices of different types, see Chapter 5 (“Device Types”) of the virtio spec ([1]). Originally developed as a standard for paravirtualized devices implemented by a hypervisor, it can be used to interface any compliant device (real or emulated) with a driver.
For illustrative purposes, this document will focus on the common case of a Linux kernel running in a virtual machine and using paravirtualized devices provided by the hypervisor, which exposes them as virtio devices via standard mechanisms such as PCI.
Although the virtio devices are really an abstraction layer in the hypervisor, they’re exposed to the guest as if they are physical devices using a specific transport method – PCI, MMIO or CCW – that is orthogonal to the device itself. The virtio spec defines these transport methods in detail, including device discovery, capabilities and interrupt handling.
The communication between the driver in the guest OS and the device in the hypervisor is done through shared memory (that’s what makes virtio devices so efficient) using specialized data structures called virtqueues, which are actually ring buffers 1 of buffer descriptors similar to the ones used in a network device:
index of the next descriptor in the chain, if the VRING_DESC_F_NEXT flag is set. We chain unused descriptors via this, too.
All the buffers the descriptors point to are allocated by the guest and used by the host either for reading or for writing but not for both.
Refer to Chapter 2.5 (“Virtqueues”) of the virtio spec ([1]) for the reference definitions of virtqueues and “Virtqueues and virtio ring: How the data travels” blog post ([2]) for an illustrated overview of how the host device and the guest driver communicate.
The vring_virtqueue struct models a virtqueue, including the ring buffers and management data. Embedded in this struct is the virtqueue struct, which is the data structure that’s ultimately used by virtio drivers:
struct virtqueue
a queue to register buffers for sending or receiving.
Definition:
1 2 3 4 5 6 7 8 9 10 11
struct virtqueue { struct list_head list; void (*callback)(struct virtqueue *vq); const char *name; struct virtio_device *vdev; unsigned int index; unsigned int num_free; unsigned int num_max; void *priv; bool reset; };
Members
list
the chain of virtqueues for this device
callback
the function to call when buffers are consumed (can be NULL).
name
the name of this virtqueue (mainly for debugging)
vdev
the virtio device this queue was created for.
index
the zero-based ordinal number for this queue.
num_free
number of elements we expect to be able to fit.
num_max
the maximum number of elements supported by the device.
priv
a pointer for the virtqueue implementation to use.
reset
vq is in reset state or not.
Description
A note on num_free: with indirect buffers, each buffer needs one element in the queue, otherwise a buffer will need one element per sg element.
The callback function pointed by this struct is triggered when the device has consumed the buffers provided by the driver. More specifically, the trigger will be an interrupt issued by the hypervisor (see vring_interrupt()). Interrupt request handlers are registered for a virtqueue during the virtqueue setup process (transport-specific).
Calls the callback function of _vq to process the virtqueue notification.
Device discovery and probing
In the kernel, the virtio core contains the virtio bus driver and transport-specific drivers like virtio-pci and virtio-mmio. Then there are individual virtio drivers for specific device types that are registered to the virtio bus driver.
How a virtio device is found and configured by the kernel depends on how the hypervisor defines it. Taking the QEMU virtio-console device as an example. When using PCI as a transport method, the device will present itself on the PCI bus with vendor 0x1af4 (Red Hat, Inc.) and device id 0x1003 (virtio console), as defined in the spec, so the kernel will detect it as it would do with any other PCI device.
内核如何发现和配置virtio设备,取决于管理程序如何定义它。以QEMU virtio-console设备为例。当使用PCI作为传输方式时,该设备将在PCI总线上以供应商0x1af4(Red Hat, Inc.)和设备ID 0x1003(virtio console)的形式出现,正如规范中所定义的那样,所以内核会像检测其他PCI设备那样检测它。
During the PCI enumeration process, if a device is found to match the virtio-pci driver (according to the virtio-pci device table, any PCI device with vendor id = 0x1af4):
if (force_legacy) { rc = virtio_pci_legacy_probe(vp_dev); /* Also try modern mode if we can't map BAR0 (no IO space). */ if (rc == -ENODEV || rc == -ENOMEM) rc = virtio_pci_modern_probe(vp_dev); if (rc) goto err_probe; } else { rc = virtio_pci_modern_probe(vp_dev); if (rc == -ENODEV) rc = virtio_pci_legacy_probe(vp_dev); if (rc) goto err_probe; }
...
rc = register_virtio_device(&vp_dev->vdev);
When the device is registered to the virtio bus the kernel will look for a driver in the bus that can handle the device and call that driver’s probe method.
At this point, the virtqueues will be allocated and configured by calling the appropriate virtio_find helper function, such as virtio_find_single_vq() or virtio_find_vqs(), which will end up calling a transport-specific find_vqs method.
VIR_CPU_TYPE_AUTO : detect the input xml to tell is guest or host cpu model definition
VIR_CPU_TYPE_GUEST : guest cpu model means the cpu conf define from domain xml
VIR_CPU_TYPE_HOST : host cpu model means the cpu conf load from host capabilities xml
So the could focus on formatFallback.
Verification is required, if you use a custom mode without a cpu model is not allowed, because custom means you need specify a collections of cpu features and custom features of the subset.
1 2 3 4 5
if (!def->model && def->mode == VIR_CPU_MODE_CUSTOM && def->nfeatures) { virReportError(VIR_ERR_INTERNAL_ERROR, "%s", _("Non-empty feature list specified without CPU model")); return-1; }
while define model, need to get a fallback value for guest cpu
The virtual CPU will claim the feature is supported regardless of it being supported by host CPU.
require
Guest creation will fail unless the feature is supported by the host CPU or the hypervisor is able to emulate it.
optional
The feature will be supported by virtual CPU if and only if it is supported by host CPU.
disable
The feature will not be supported by virtual CPU.
forbid
Guest creation will fail if the feature is supported by host CPU.
virCPUDefFormatBuf is used by capabilities.c which collects host features from host capabilities xml. But now we need to check the code in domain_capabilities.c
typedef virCPUDef *virCPUDefPtr; struct _virCPUDef { int type; /* enum virCPUType */ int mode; /* enum virCPUMode */ int match; /* enum virCPUMatch */ virCPUCheck check; virArch arch; char *model; char *vendor_id; /* vendor id returned by CPUID in the guest */ int fallback; /* enum virCPUFallback */ char *vendor; unsignedint microcodeVersion; unsignedint sockets; unsignedint cores; unsignedint threads; size_t nfeatures; size_t nfeatures_max; virCPUFeatureDefPtr features; virCPUCacheDefPtr cache; };
nfeatures will be set in _virCPUDef and supported features are parsed from domain xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* * Parses CPU definition XML from a node pointed to by @xpath. If @xpath is * NULL, the current node of @ctxt is used (i.e., it is a shortcut to "."). * * Missing <cpu> element in the XML document is not considered an error unless * @xpath is NULL in which case the function expects it was provided with a * valid <cpu> element already. In other words, the function returns success * and sets @cpu to NULL if @xpath is not NULL and the node pointed to by * @xpath is not found. * * Returns 0 on success, -1 on error. */ int virCPUDefParseXML(xmlXPathContextPtr ctxt, constchar *xpath, virCPUType type, virCPUDefPtr *cpu)
Finally, qemu_command.c would use those features to qemu commandline:
for (i = 0; i < cpu->nfeatures; i++) { if (STREQ("rtm", cpu->features[i].name)) rtm = true; if (STREQ("hle", cpu->features[i].name)) hle = true;
switch ((virCPUFeaturePolicy) cpu->features[i].policy) { case VIR_CPU_FEATURE_FORCE: case VIR_CPU_FEATURE_REQUIRE: if (virQEMUCapsGet(qemuCaps, QEMU_CAPS_QUERY_CPU_MODEL_EXPANSION)) virBufferAsprintf(buf, ",%s=on", cpu->features[i].name); else virBufferAsprintf(buf, ",+%s", cpu->features[i].name); break;
case VIR_CPU_FEATURE_DISABLE: case VIR_CPU_FEATURE_FORBID: if (virQEMUCapsGet(qemuCaps, QEMU_CAPS_QUERY_CPU_MODEL_EXPANSION)) virBufferAsprintf(buf, ",%s=off", cpu->features[i].name); else virBufferAsprintf(buf, ",-%s", cpu->features[i].name); break;
case VIR_CPU_FEATURE_OPTIONAL: case VIR_CPU_FEATURE_LAST: break; } }
like -cpu ... feature1=on,feature2=off to make those features take effects.
oc = cpu_class_by_name(CPU_RESOLVING_TYPE, model_pieces[0]); if (oc == NULL) { error_report("unable to find CPU model '%s'", model_pieces[0]); g_strfreev(model_pieces); exit(EXIT_FAILURE); }
An object from oc = cpu_class_by_name(CPU_RESOLVING_TYPE, model_pieces[0]);will return a cpu object class which support parse features. See following code:
eq = strchr(featurestr, '='); if (eq) { *eq++ = 0; val = eq; } else { val = "on"; }
feat2prop(featurestr); name = featurestr;
if (g_list_find_custom(plus_features, name, compare_string)) { warn_report("Ambiguous CPU model string. " "Don't mix both \"+%s\" and \"%s=%s\"", name, name, val); ambiguous = true; } if (g_list_find_custom(minus_features, name, compare_string)) { warn_report("Ambiguous CPU model string. " "Don't mix both \"-%s\" and \"%s=%s\"", name, name, val); ambiguous = true; }
/* Special case: */ if (!strcmp(name, "tsc-freq")) { int ret; uint64_t tsc_freq;
ret = qemu_strtosz_metric(val, NULL, &tsc_freq); if (ret < 0 || tsc_freq > INT64_MAX) { error_setg(errp, "bad numerical value %s", val); return; } snprintf(num, sizeof(num), "%" PRId64, tsc_freq); val = num; name = "tsc-frequency"; }
/* Check for missing features that may prevent the CPU class from * running using the current machine and accelerator. */ staticvoidx86_cpu_class_check_missing_features(X86CPUClass *xcc, strList **missing_feats) { X86CPU *xc; Error *err = NULL; strList **next = missing_feats;
x86_cpu_expand_features(xc, &err); if (err) { /* Errors at x86_cpu_expand_features should never happen, * but in case it does, just report the model as not * runnable at all using the "type" property. */ strList *new = g_new0(strList, 1); new->value = g_strdup("type"); *next = new; next = &new->next; }
/* * Finishes initialization of CPUID data, filters CPU feature * words based on host availability of each feature. * * Returns: 0 if all flags are supported by the host, non-zero otherwise. */ staticvoidx86_cpu_filter_features(X86CPU *cpu, bool verbose) { CPUX86State *env = &cpu->env; FeatureWord w; constchar *prefix = NULL;
if (verbose) { prefix = accel_uses_host_cpuid() ? "host doesn't support requested feature" : "TCG doesn't support requested feature"; }
for (w = 0; w < FEATURE_WORDS; w++) { uint64_t host_feat = x86_cpu_get_supported_feature_word(w, false); uint64_t requested_features = env->features[w]; uint64_t unavailable_features = requested_features & ~host_feat; mark_unavailable_features(cpu, w, unavailable_features, prefix); }
the hypervisor guest status = false value changed as expected.
Linux drawbacks
Read the usage about X86_FEATURE_HYPERVISOR in linux kernel. Some drawbacks can be found in kernel code directly.
From qspintlock.h :
1 2 3 4 5 6 7 8 9 10 11 12 13
/* * RHEL7 specific: * To provide backward compatibility with pre-7.4 kernel modules that * inlines the ticket spinlock unlock code. The virt_spin_lock() function * will have to recognize both a lock value of 0 or _Q_UNLOCKED_VAL as * being in an unlocked state. */ staticinlineboolvirt_spin_lock(struct qspinlock *lock) { int lockval;
if (!static_cpu_has(X86_FEATURE_HYPERVISOR)) returnfalse;
/* * Don't enable ART in a VM, non-stop TSC required, * and the TSC counter resets must not occur asynchronously. */ if (boot_cpu_has(X86_FEATURE_HYPERVISOR) || !boot_cpu_has(X86_FEATURE_NONSTOP_TSC) || art_to_tsc_denominator < ART_MIN_DENOMINATOR || tsc_async_resets) return;
Always run timer will be started which actually should not be enabled.
From apic.c:
1 2 3
if (!boot_cpu_has(X86_FEATURE_TSC_DEADLINE_TIMER) || boot_cpu_has(X86_FEATURE_HYPERVISOR)) return;
From mshyperv.c:
1 2
if (!boot_cpu_has(X86_FEATURE_HYPERVISOR)) return0;
Can not detect if run on hyperv.
From radeon_device :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/** * radeon_device_is_virtual - check if we are running is a virtual environment * * Check if the asic has been passed through to a VM (all asics). * Used at driver startup. * Returns true if virtual or false if not. */ boolradeon_device_is_virtual(void) { #ifdef CONFIG_X86 return boot_cpu_has(X86_FEATURE_HYPERVISOR); #else returnfalse; #endif }
Radeon gpu will not detect it is running as guest.
For kernel it may failed to detect that it is running over hypervisor. So related performance improvement changed won’t be applied so there will be a performance drop for those guests.
So does the userspace application also can not do specific things without knowing it is running in virtual machine.
While the split virtqueue shines because of the simplicity of its design, it has a fundamental problem: The avail-used buffer cycle needs to use memory in a very sparse way. This puts pressure on the CPU cache utilization, and in the case of hardware means several PCI transactions for each descriptor.
Packed virtqueue amends it by merging the three rings in just one location in virtual environment guest memory. While this may seem complicated at first glance, it’s a natural step after the split version if we realize that the device can discard and overwrite the data it already has read from the driver, and the same happens the other way around.
Supplying descriptors to the device: How to fill device todo-list
After initialization in the same process as described in Virtio device initialization: feature bits, and after the agreement on RING_PACKED feature flag, the driver and the device starts with a shared blank canvas of descriptors with an agreed length (up to 215 entries) in a agreed guest’s memory location. The layout of these descriptors is:
This time, the id field is not an index for the device to look for the buffer: it is an opaque value for it, only has meaning for the driver.
The driver also maintains an internal single-bit ring wrap counter initialized to 1. The driver will flip its value every time it makes available the last descriptor in the ring.
As with split descriptors, the first step is to write the different fields: address, length, id and flags. However, packed descriptors take into account two new flags: AVAIL(0x7) and USED(0x15). To mark a descriptor as available, the driver makes the AVAIL(0x7) flag the same as its internal wrap counter, and the used flag the inverse. While just a binary flag avail/used would be easier to implement, it would prevent useful optimizations we will describe later.
As an example, if the driver allocates a write buffer with 0x1000 bytes on position 0x80000000 in the step 1 in the diagram, and makes it the first available descriptor setting AVAIL(0x7) flag the same as internal wrap counter (set) in step 2. The descriptor table would look like this:
Avail idx
Address
Length
ID
Flags
Used idx
0x80000000
0x1000
0
W|A
←
→
…
Figure: Descriptor table after add the first buffer
Note that the avail and used idx columns are in the table just for guidance, they don’t exist in the descriptor table: Each side should have its internal counter to know which position needs to poll or write next, and also the device must track the driver’s wrap counter. Lastly, as with used virtqueue, the driver notifies the device if the latter has notifications enabled (step 3 in the diagram).
And the usual diagram of the updates. Note the lack of the avail and used ring, as only the descriptor table is needed now.
还有通常的更新图。请注意,由于现在只需要描述符表,所以缺少可用和已用环。
Diagram: Driver makes available a descriptor using a packed queue
Returning used descriptors: How the device fills the “done” list
As the driver, the device maintains an internal single-bit ring wrap counter initialized to 1, and knows that the driver also has its internal ring wrap counter set. When the latter first searches for the first descriptor the driver has made available, it polls the first entry of the ring, looking for the avail flag equal to the driver internal wrap flag (set in this case).
As with a used ring, the length of the written data is returned in the “length” entry (if any), and the id of the used descriptor. At last, the device will make the avail (A) and used (U) flag the same as the device’s internal wrap counter.
Following the example, the device will let the descriptor table as figure 6. The device will know that the buffer has been returned because the used flag matches the available flag, and with the device internal wrap counter at the moment it wrote the descriptor. The returned address is not important: only the ID.
Avail idx
Address
Length
ID
Flags
Used idx
0x80000000
0x1000
0
W|A|U
→
…
←
Figure: Descriptor table after add the first buffer
Diagram: Device marks a descriptor as used using a packed queue
Wrapping the descriptor ring: How the lanes keep separated?
When the driver fills the complete descriptor table, it wraps and changes its internal Driver Ring Wrap. So, in the second round, the available descriptions will have the avail and used flags clear, so the device will have to poll looking for this condition once it wraps reading descriptors. Let’s see a full example of the different situations.
If we have a descriptor table with only two entries, the Driver Ring Wrap Counter is set, and it fills the descriptor table making available two buffers at the beginning of the operation, driver will reverse its internal wrap counter, so it will be clear (0). We have the next table:
After that, the device realizes that has both descriptors with id #0 and #1 available: it knows that the driver had its wrap counter set when it wrote them, the avail flag is set on them, and the used one is clear on both. If device uses the descriptor with id #1, we have the Figure 8 descriptor table. The buffer #0 still belongs to the device!
Now the driver realize the buffer #1 has been used, since avail and used flags are the same (set) and match the device’s internal wrap counter at the moment it wrote it. If device now uses the buffer id #0, it will make the table look like this:
But there is a more interesting case: Starting from the “first buffer out of order” situation, the driver makes available the buffer #1 again. In that case, the descriptor table goes directly from the “first buffer” to the next figure, “Full two-entries descriptor table.”
Chained descriptors work likewise: no need for the next field in the head (or subsequent) descriptor in the chain to search subsequent ones, since the latter always occupies the next position. However, while in the split used ring you only need to return as used the id of the head of the chain, in packed you only need to return the tail id.
Back to the used ring, every time we use chained descriptors, we make the used idx lag regarding the avail idx. More than one descriptor mark as available to the device, but we only send one as used to the driver. While this is not a problem in the split ring, this would cause descriptor entry exhaustion in the packed version.
The straightforward solution is to make the device mark as used every descriptor in the chain. However, this can be expensive, since we are modifying a shared area of memory, and could cause cache bounces.
However, the driver already knows the chain, so it can skip all the chain with only the last id. This is why we need to compare the used/avail pair with the driver/device Wrap Counter: after a jump, we wouldn’t know if the next descriptor has been made available in this driver’s round or in the next if we only have a binary available/used flag.
For example, in a four entries ring, the driver makes available the chain of three descriptors:
Avail idx
Address
Length
ID
Flags
Used idx
0x80000000
0x1000
0
W|A
←
0x81000000
0x1000
1
W|A
0x82000000
0x1000
2
W|A
→
0
Figure: Three chained descriptors available
例如,在一个四项环中,驱动器提供了三个描述符的链。
After that, the device discovers the chain (polling position 0) and marks it as used, overwriting only the position 0. It skips completely the positions 1 and 2. When the driver polls for used, it will skip them too, knowing that the chain was 3 descriptors long:
Now the driver produces another two descriptor long chain, and it has to take into account the wrapping:
Avail idx
Address
Length
ID
Flags
Used idx
0x81000000
0x1000
1
W|(!A)|U
→
0x81000000
0x1000
1
W|A
0x82000000
0x1000
2
W|A
0x80000000
0x1000
0
W|A
←
Figure: Make available another descriptor chain
现在,驱动程序又产生了一个两根描述符的长链,它必须考虑到包装的问题。
And the device marks it as used, so only the first descriptor in the chain (4th in the table) needs to be updated.
Avail idx
Address
Length
ID
Flags
Used idx
0x81000000
0x1000
1
W|(!A)|U
→
0x81000000
0x1000
1
W|A
←
0x82000000
0x1000
2
W|A
0x80000000
0x1000
0
W|A|U
Figure: Using another descriptor chain
Although the next descriptor (2nd) seems like available, since the avail flag is different from the used one, the device knows that it is not because of knowing the internal Driver Wrap Counter: The right flag combination is avail clear, used set.
Indirect descriptors work like in the split case. First, the driver allocates a table of indirect descriptors each with the same layout as the regular packed descriptors anywhere in memory. After that, it sets each descriptor in this indirect table to the buffer it wants to make available for the driver (steps 1-2), and inserts a descriptor in the virtqueue with the flag VIRTQ_DESC_F_INDIRECT (0x4) set (step 3). The descriptor’s address and length correspond to the indirect table’s ones.
In packed layout buffers must come in order in the indirect table, and the ID field is completely ignored. Also, the only valid flag for them is VIRTQ_DESC_F_WRITE, others are reserved and ignored by the device. As usual, the driver will notify the device if the conditions for the notification are met (step 4).
Diagram: Driver makes available a descriptor using a packed queue
For example, the driver would need to allocate this 48 bytes table for a 3 descriptors indirect table:
Address
Length
ID
Flags
0x80000000
0x1000
…
W
0x81000000
0x1000
…
W
0x82000000
0x1000
…
W
Figure: Three descriptor long indirect packed table
And if it introduces the indirect table the first in the descriptor table, assuming it is allocated in 0x83000000 address:
Avail idx
Address
Length
ID
Flags
Used idx
0x80000000
48
0
A|I
←
→
…
Figure: Drivers makes an indirect table available
After indirect buffer consumption, the device needs to return the indirect buffer id (0 in the example) in its used descriptor. The table looks like the return of the first buffer, except for the indirect (I) flag set:
Avail idx
Address
Length
ID
Flags
Used idx
0x80000000
48
0
A|U|I
→
…
←
Figure: Device makes an indirect table used
After that, the device cannot access the memory table anymore unless the driver makes it available again, so the latter can free or reuse it.
Notifications: how to manage interruptions?
Like in the used queue, each side of the communication maintains two identical structures used for controlling notifications between the device and the driver. The driver’s one is read-only by the device, and the device’s one is read-only by the driver.
2: Notifications are enabled for a specific descriptor, specified from the desc member.
If flags value is 2, the other side will notify until the wrap counter matches the most significant bit of desc and the descriptor placed in the position desc discarding that bit is made used/available. For this mode to work, VIRTIO_F_RING_EVENT_IDX flag needs to be negotiated in Virtio device initialization: feature bits.
None of these mechanisms are 100% reliable, since the other side could have sent the notification already when we set the values, so expect it even when disable.
Note that, since the descriptor ring size is not being forced to be a power of two (comparing with the split version), the notification structure can fit in the same page as the descriptor table. This can be advantageous for some implementations.
In this series we have taken you through the different virtio data plane layouts and its virtqueues implementations. They are the means for virtio devices and virtio drivers to exchange information.
We start by covering the simpler and less optimized split virtqueue layout. This layout is relatively easy to implement and to debug thus it’s a good entry point for learning the virtio dataplane basics.
We then moved on to the packed virtqueue layout specified in virtio 1.1 which allows requests exchange using a more compact descriptor representation. This avoids all the overhead of scattering the data through memory, avoiding cache contention and reducing the PCI transactions in case of actual hardware.
We also covered a number of optimizations on top of both ring layouts which depends on the communication/device type or how each part is implemented. Mainly, they are oriented to reduce the communication overhead, both in notifications and in memory transactions. Virtio offers a simple protocol to communicate what features and optimizations support each side, so they can agree on how the data is going to be exchanged and is highly future-proof.
This series covered the essence of the virtio data plane and provided you with the tool to analyze and develop your own virtio device and drivers. It should be noted that this series summarizes the relevant sections from the virtio spec thus you should refer to the spec for additional information and see it as the source of truth.
In the next posts we will return to vDPA including the kernel framework, hands on blogs and vDPA in Kubernetes.